专题:https://www.zhihu.com/column/c_1444067713429327872
文章目录
工具:https://gcc.godbolt.org/
1、基本汇编概念
32位和64位处理器之间的主要区别通常包括:
-
数据总线宽度: 32位处理器通常有32位数据总线,而64位处理器通常有64位数据总线。这意味着他们一次可以读取或写入的数据量分别是32位和64位。
-
寄存器宽度: 在64位处理器上,通用寄存器通常是64位宽的,而在32位处理器上,通用寄存器通常是32位宽。
-
内存寻址: 64位处理器通常可以访问更大的内存空间。因为它们使用64位的地址,所以理论上可以寻址高达18.4 million TB(约 (2^{64}) 字节)的内存,而32位处理器最多只能寻址4GB((2^{32}) 字节)的内存。
-
系统支持: 与64位处理器相配套的操作系统和应用程序能够更有效地利用这些硬件特性。
值得注意的是,即使是64位处理器,也通常能够在32位模式下运行,以便与旧的软件兼容。
但这并不意味着64位处理器总是一次只处理64位数据,或者32位处理器一次只处理32位数据。例如,许多现代处理器有SIMD(单指令多数据流)指令,它们一次可以处理多个数据项,即使每个数据项的大小超过了基本的32位或64位。另外,有些特定的操作(例如,浮点运算)可能会使用不同大小的寄存器。所以,一次能处理的数据量实际上取决于具体执行的指令和操作。
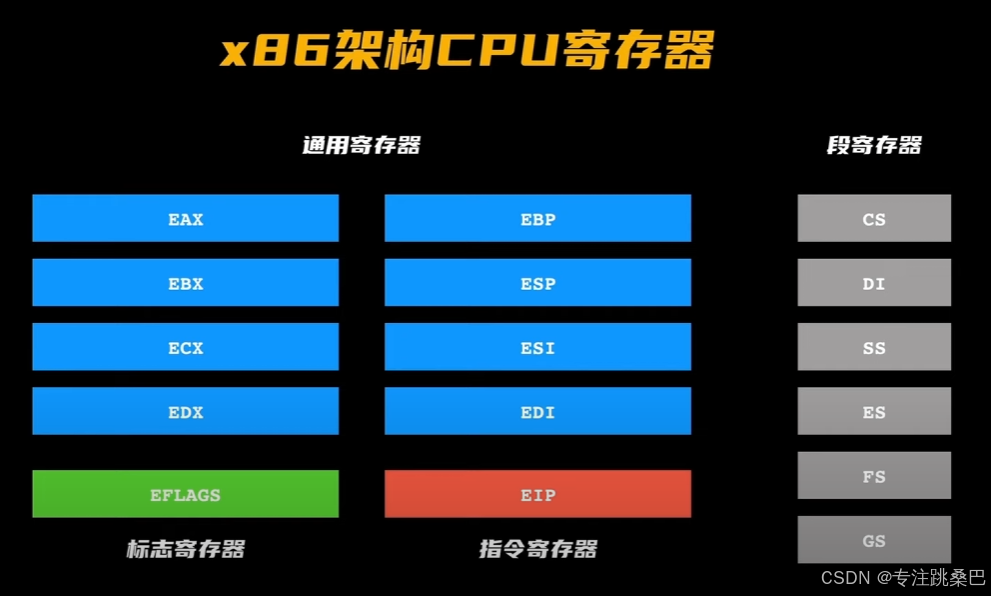
Ⅰ、常用寄存器
CPU的指令,可以处理两种尺寸的数据,byte(8位)和word(16位)【根据具体编译器32/64】
所以在机器指令中要指明,指令进行的是字操作还是字节操作。一般都是按word字来处理。


常用汇编命令
-
mov: 数据传输指令,用于将数据从一个位置复制到另一个位置。例如,mov eax, ebx将ebx的值复制到eax。 -
add: 加法指令,用于执行加法运算。例如,add eax, ebx将eax和ebx的值相加,并将结果存储到eax。
push
push: 压栈指令,将一个值压入堆栈。例如,push eax将eax中的值压入堆栈。
pop
-
pop: 出栈指令,将栈顶的值弹出到指定位置。例如,pop ebx将堆栈顶部的值弹出到ebx。 -
xor: 异或指令,对两个操作数执行按位异或运算,并将结果存储到目标操作数中。例如,xor eax, ebx将eax和ebx的位进行异或运算,并将结果存储到eax。 -
lea: 加载有效地址指令,用于计算并加载内存地址。例如,lea edi, [eax + ebx*2]将eax和ebx的值相加,并将结果的内存地址存储到edi。 -
call: 调用指令,用于调用子程序或函数。例如,call SomeFunction将程序控制转移到SomeFunction函数的起始位置,并在返回时继续执行。 -
jmp: 无条件跳转指令,直接将程序控制转移到指定的目标地址。例如,jmp label将程序控制无条件地转移到label处。 -
sub: 减法指令,用于执行减法运算。例如,sub eax, ebx将ebx的值从eax中减去,并将结果存储到eax。 -
ret: 返回指令,用于返回调用子程序或函数的位置,并将程序控制返回到调用点。 -
cmp: 比较指令,用于比较两个操作数的大小,并根据比较结果设置标志位。 -
jXX: 条件跳转指令,根据标志位的状态来决定是否跳转到指定的目标地址。 -
inc: 递增指令,将指定寄存器或内存位置的值加一。 -
dec: 递减指令,将指定寄存器或内存位置的值减一。 -
mul: 无符号乘法指令,用于执行无符号整数的乘法运算。 -
div: 无符号除法指令,用于执行无符号整数的除法运算。 -
loop: 循环指令,根据计数器的值进行循环。当计数器不为零时,跳转到指定目标地址。 -
and: 与操作指令,对两个操作数的对应位进行逻辑与操作,并将结果存储到目标操作数中。 -
or: 或操作指令,对两个操作数的对应位进行逻辑或操作,并将结果存储到目标操作数中。 -
not: 取反操作指令,对指定操作数的每一位执行逻辑取反操作。 -
nop:noOperation 无操作可能比如为了对齐,或者就是空
ret
ret:return的缩写,主要是为了回到原来的位置
- 在汇编语言中,
ret是 “return” 的缩写,用于从函数调用返回。当程序执行到ret指令时,它会从堆栈中弹出一个返回地址,并将指令指针(在 x86 和 x86-64 架构中通常是eip或rip寄存器)设置为这个地址,从而继续执行调用函数(也称为“调用者”)中的下一条指令。
下面是对以上汇编指令的整理:
- 数据传输指令:
mov: 数据传输指令,用于将数据从一个位置复制到另一个位置。例如:mov eax, ebx
- 算术运算指令:
add: 加法指令,用于执行加法运算。例如:add eax, ebxsub: 减法指令,用于执行减法运算。例如:sub eax, ebxmul: 无符号乘法指令,用于执行无符号整数的乘法运算。例如:mul ecxdiv: 无符号除法指令,用于执行无符号整数的除法运算。例如:div ebx
- 栈操作指令:
push: 压栈指令,将一个值压入堆栈。例如:push eaxpop: 出栈指令,将栈顶的值弹出到指定位置。例如:pop ebx
- 位运算指令:
xor: 异或指令,对两个操作数执行按位异或运算,并将结果存储到目标操作数中。例如:xor eax, ebxand: 与操作指令,对两个操作数的对应位进行逻辑与操作,并将结果存储到目标操作数中。例如:and eax, ebxor: 或操作指令,对两个操作数的对应位进行逻辑或操作,并将结果存储到目标操作数中。例如:or eax, ebxnot: 取反操作指令,对指定操作数的每一位执行逻辑取反操作。例如:not eax
- 控制流程指令:
jmp: 无条件跳转指令,直接将程序控制转移到指定的目标地址。例如:jmp labelcall: 调用指令,用于调用子程序或函数。例如:call SomeFunctionret: 返回指令,用于返回调用子程序或函数的位置,并将程序控制返回到调用点。
- 条件跳转指令:
cmp: 比较指令,用于比较两个操作数的大小,并根据比较结果设置标志位。例如:cmp eax, ebxjXX: 条件跳转指令,根据标志位的状态来决定是否跳转到指定的目标地址。例如:je label
- 地址计算指令:
lea
lea: 加载有效地址指令,用于计算并加载内存地址。例如:lea edi, [eax + ebx*2]
lea rax, [rbp-24]:这条指令的全称是"Load Effective Address"(加载有效地址)。它会计算出有效地址[rbp-24]并将其存储到rax寄存器中。基本上,这个指令在基址指针rbp相对的内存位置设置了一个用于存储MyClass对象的空间。
- 循环指令:
loop: 循环指令,根据计数器的值进行循环。例如:loop labelinc: 递增指令,将指定寄存器或内存位置的值加一。例如:inc ecxdec: 递减指令,将指定寄存器或内存位置的值减一。例如:dec ecx
这些指令在汇编语言中被广泛使用,用于实现各种功能,如数据传输、运算、控制流程和地址计算等。根据具体需求和上下文环境,可以选择适当的指令来实现相应的功能。
寄存器:rbp、rsp
rsp 和 rbp 是 x86-64 架构下的寄存器。
-
rsp(Register Stack Pointer)是栈指针寄存器,完整的全称是 “64-bit Register Stack Pointer”。它包含了当前栈帧的栈顶地址,用于指向栈中最近被压入的数据。该指针总指向栈的顶部(低地址) -
rbp(Register Base Pointer)是基址指针寄存器,完整的全称是 “64-bit Register Base Pointer”。它通常指向当前函数栈帧的底部,用于访问函数的局部变量和参数。该指针总是指向当前栈帧的底部(高地址) -
32位是esp和ebp
寄存器:rax、rip
x86-64 架构下常用寄存器
以下是对 x86-64 架构下常用寄存器的功能和作用的解释,以MVSC 2019为例:
typedef struct _WHEA_X64_REGISTER_STATE {ULONGLONG Rax;
ULONGLONG Rbx;
ULONGLONG Rcx;
ULONGLONG Rdx;
ULONGLONG Rsi;
ULONGLONG Rdi;
ULONGLONG Rbp;
ULONGLONG Rsp;
ULONGLONG R8;
ULONGLONG R9;
ULONGLONG R10;
ULONGLONG R11;
ULONGLONG R12;
ULONGLONG R13;
ULONGLONG R14;
ULONGLONG R15;
USHORT Cs;
USHORT Ds;
USHORT Ss;
USHORT Es;
USHORT Fs;
USHORT Gs;
ULONG Reserved;
ULONGLONG Rflags;
ULONGLONG Eip;
ULONGLONG Cr0;
ULONGLONG Cr1;
ULONGLONG Cr2;
ULONGLONG Cr3;
ULONGLONG Cr4;
ULONGLONG Cr8;
WHEA128A Gdtr;
WHEA128A Idtr;
USHORT Ldtr;
USHORT Tr;
} WHEA_X64_REGISTER_STATE, *PWHEA_X64_REGISTER_STATE;
以下是 WHEA_X64_REGISTER_STATE 结构体中每个成员变量的寄存器功能介绍:
Rax: 通用寄存器,用于存储函数返回值或通用数据。Rip:指令指针寄存器,存储下一条将要执行的指令的地址。Rbx: 通用寄存器,用于存储通用数据。Rcx: 通用寄存器,用于存储通用数据。Rdx: 通用寄存器,用于存储通用数据。Rsi: 通用寄存器,用于存储通用数据。Rdi: 通用寄存器,用于存储通用数据。Rbp: 通用寄存器,用于存储栈帧基址指针。Rsp: 通用寄存器,用于存储栈指针,指向当前栈的顶部。R8-R15: 通用寄存器,用于存储通用数据。Cs: 代码段寄存器,用于存储当前代码段选择子。Ds: 数据段寄存器,用于存储当前数据段选择子。Ss: 栈段寄存器,用于存储当前栈段选择子。Es: 附加段寄存器,用于存储当前附加段选择子。Fs: 附加段寄存器,用于存储当前附加段选择子。Gs: 附加段寄存器,用于存储当前附加段选择子。Reserved: 保留字段。Rflags: 标志寄存器,存储了一些处理器的标志位信息,例如进位标志、零标志等。Eip: 指令指针寄存器,用于存储下一条要执行的指令的地址。Cr0-Cr4: 控制寄存器,包含一些控制处理器行为的位。Cr8: 控制寄存器,用于存储当前任务优先级。Gdtr: 全局描述符表寄存器,存储全局描述符表的起始地址和限制。Idtr: 中断描述符表寄存器,存储中断描述符表的起始地址和限制。Ldtr: 局部描述符表寄存器,用于存储局部描述符表的选择子。Tr: 任务寄存器,用于存储任务状态段的选择子。
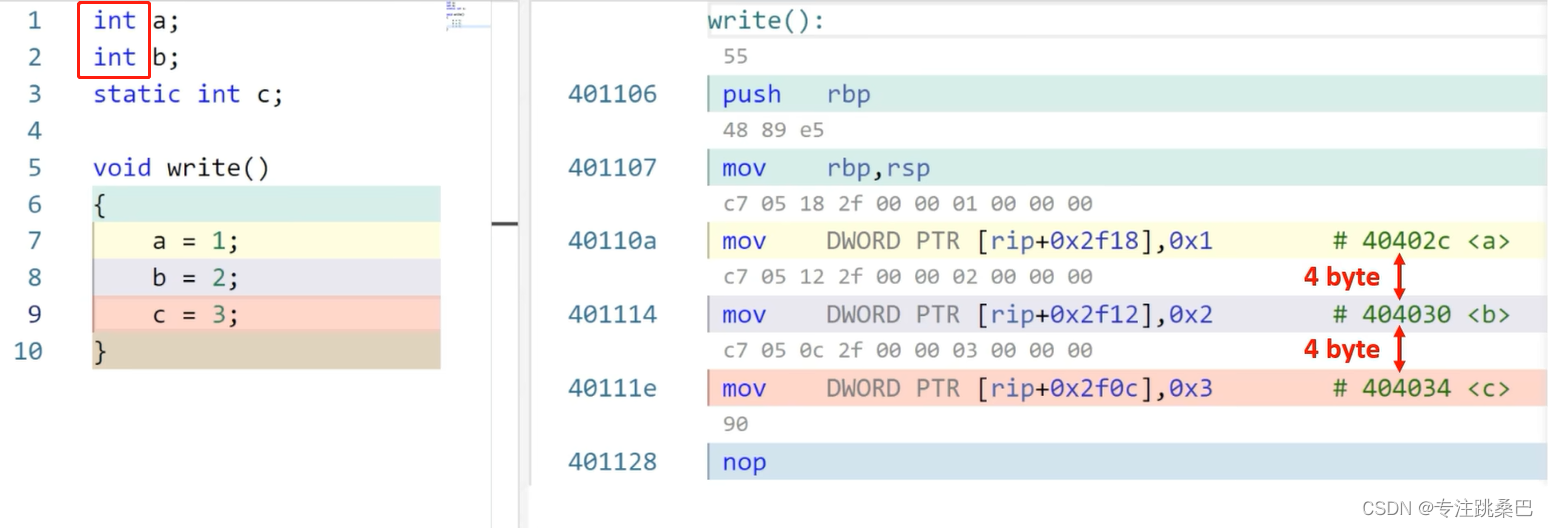
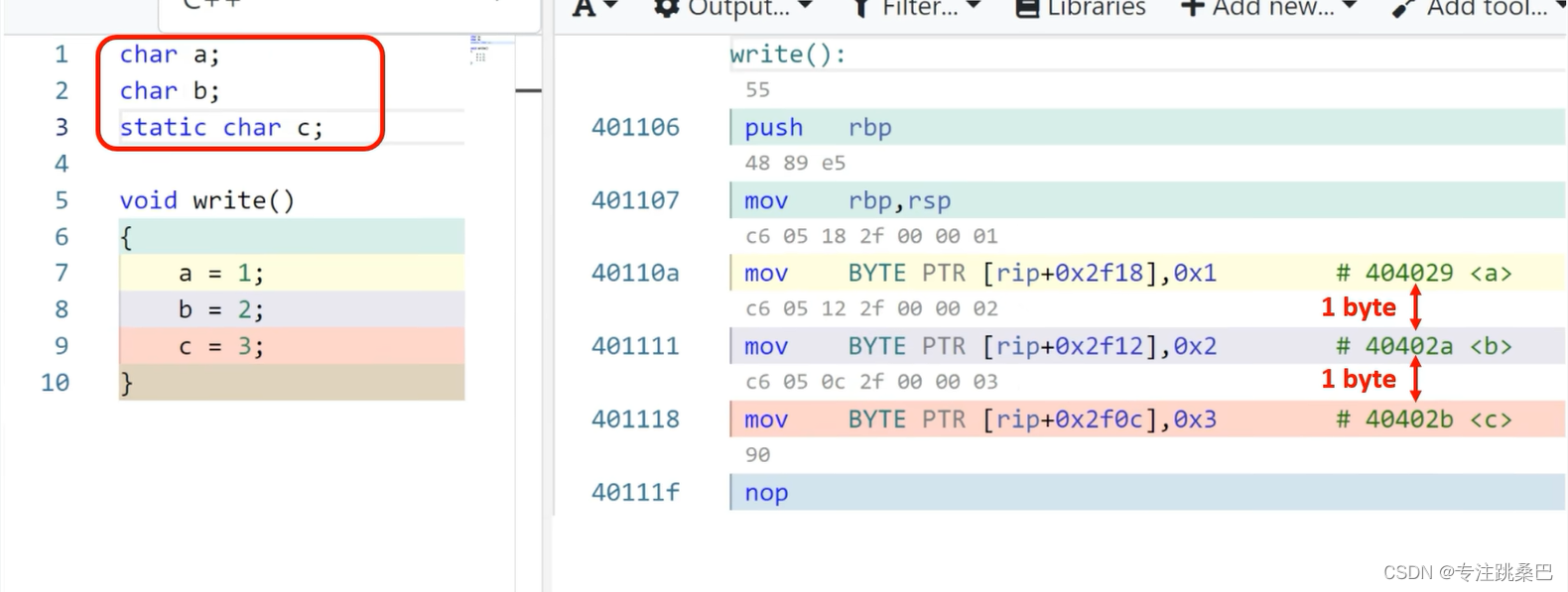
Ⅱ、例1:变量声明和赋值

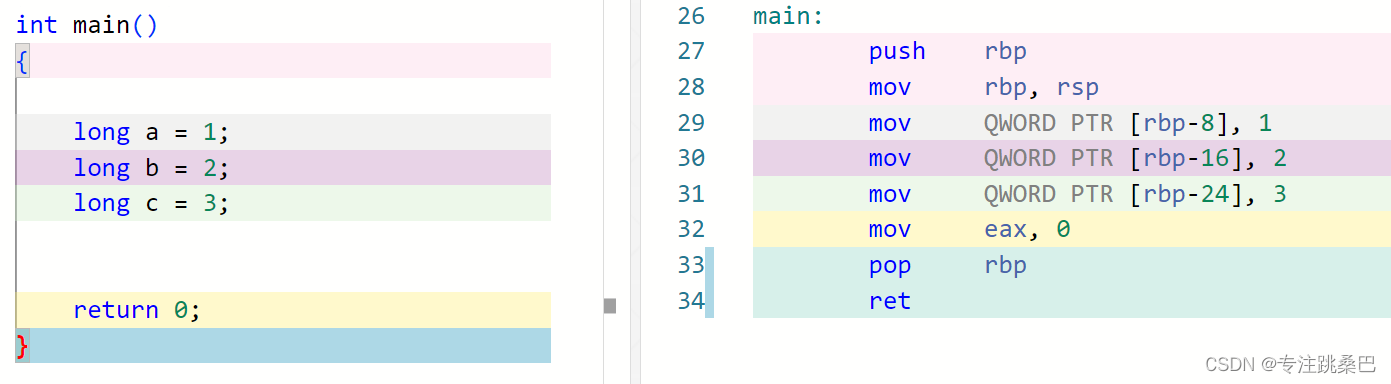
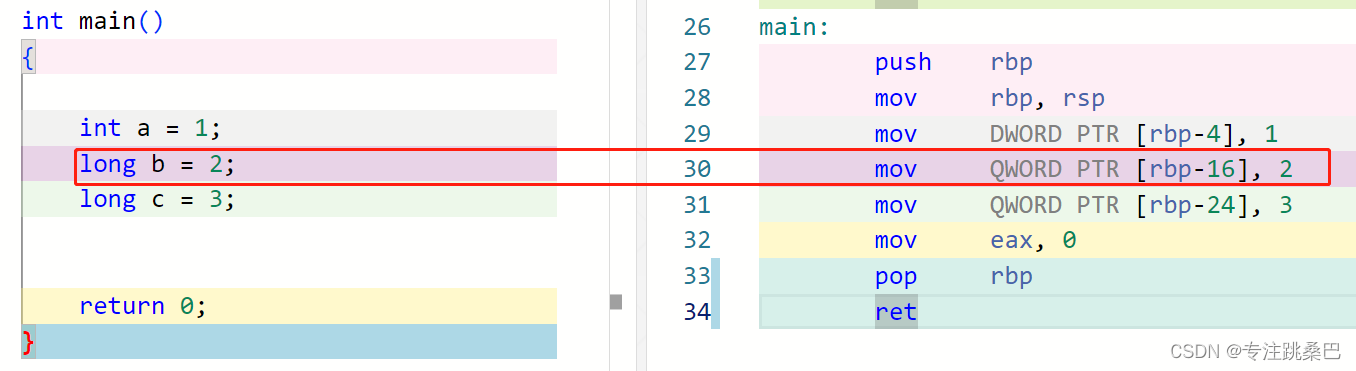
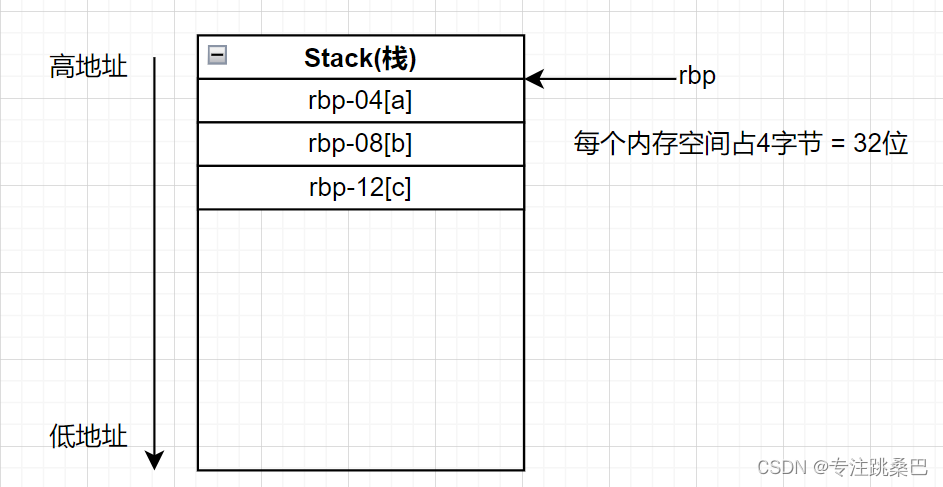
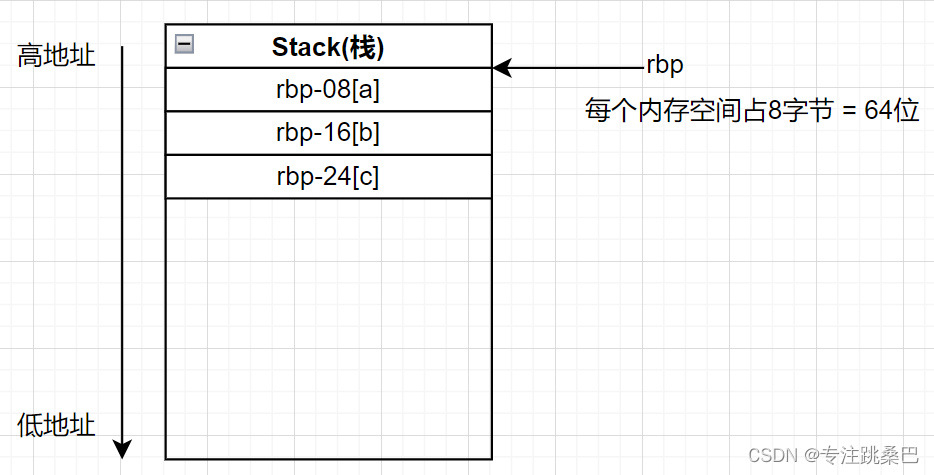
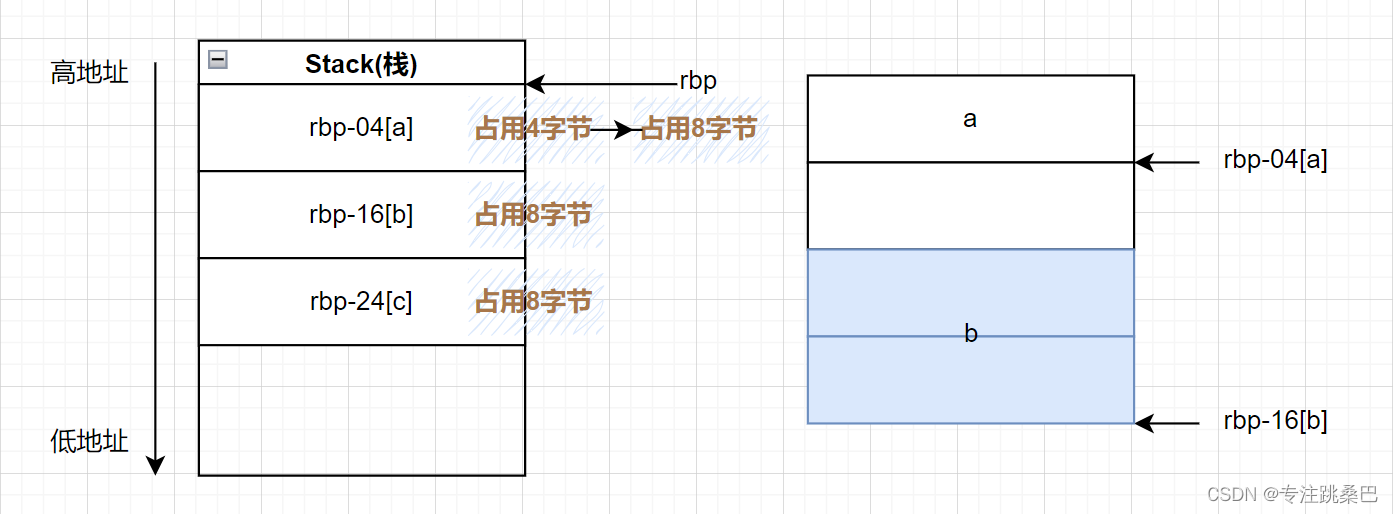
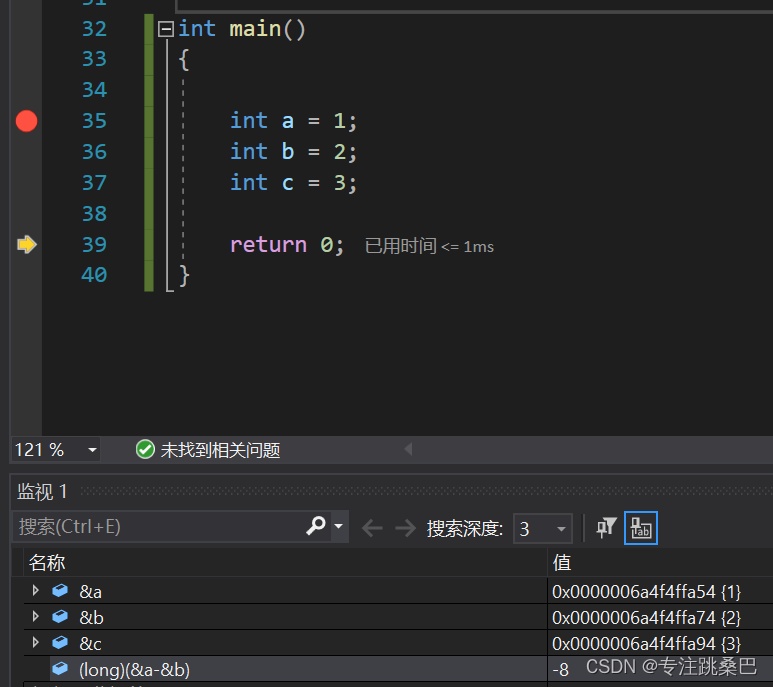
总结:
- 变量和赋值声明对应汇编的意思
- 内存对齐的意义
- 32位和64位编译器的初步认识
- 在vs2019中没有明显差别,编译器都进行了优化
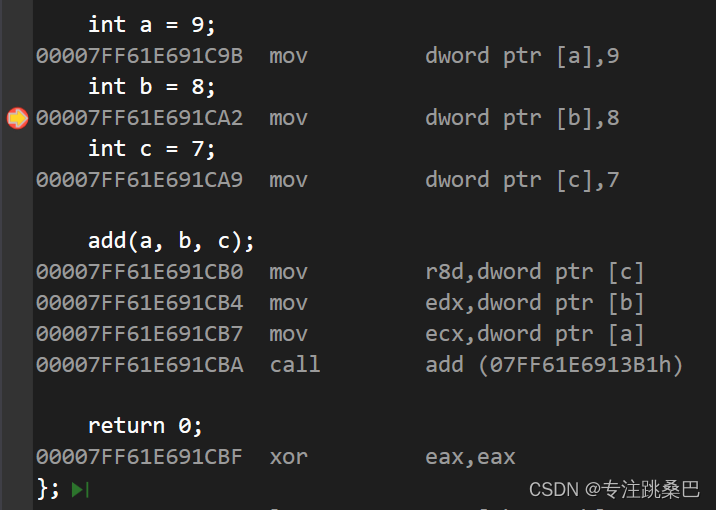
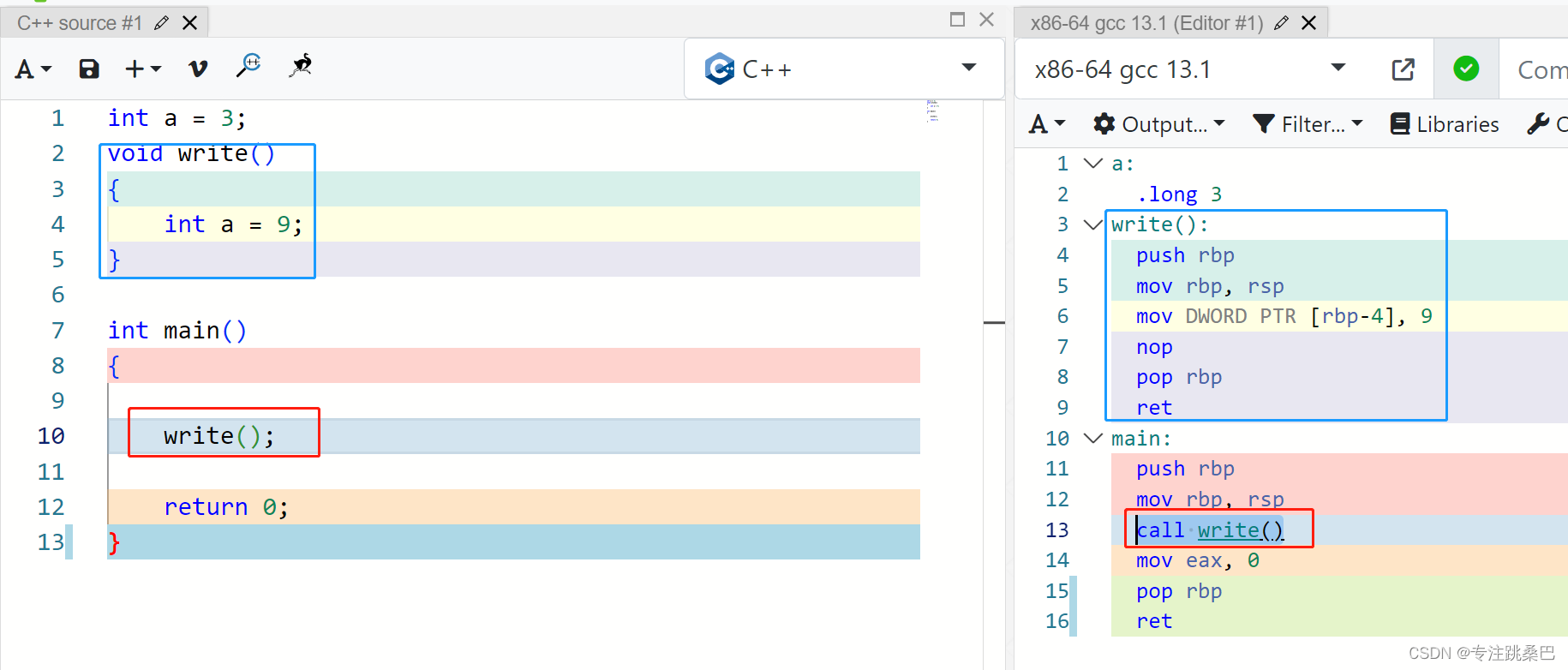
Ⅲ、例2:函数的基础调用
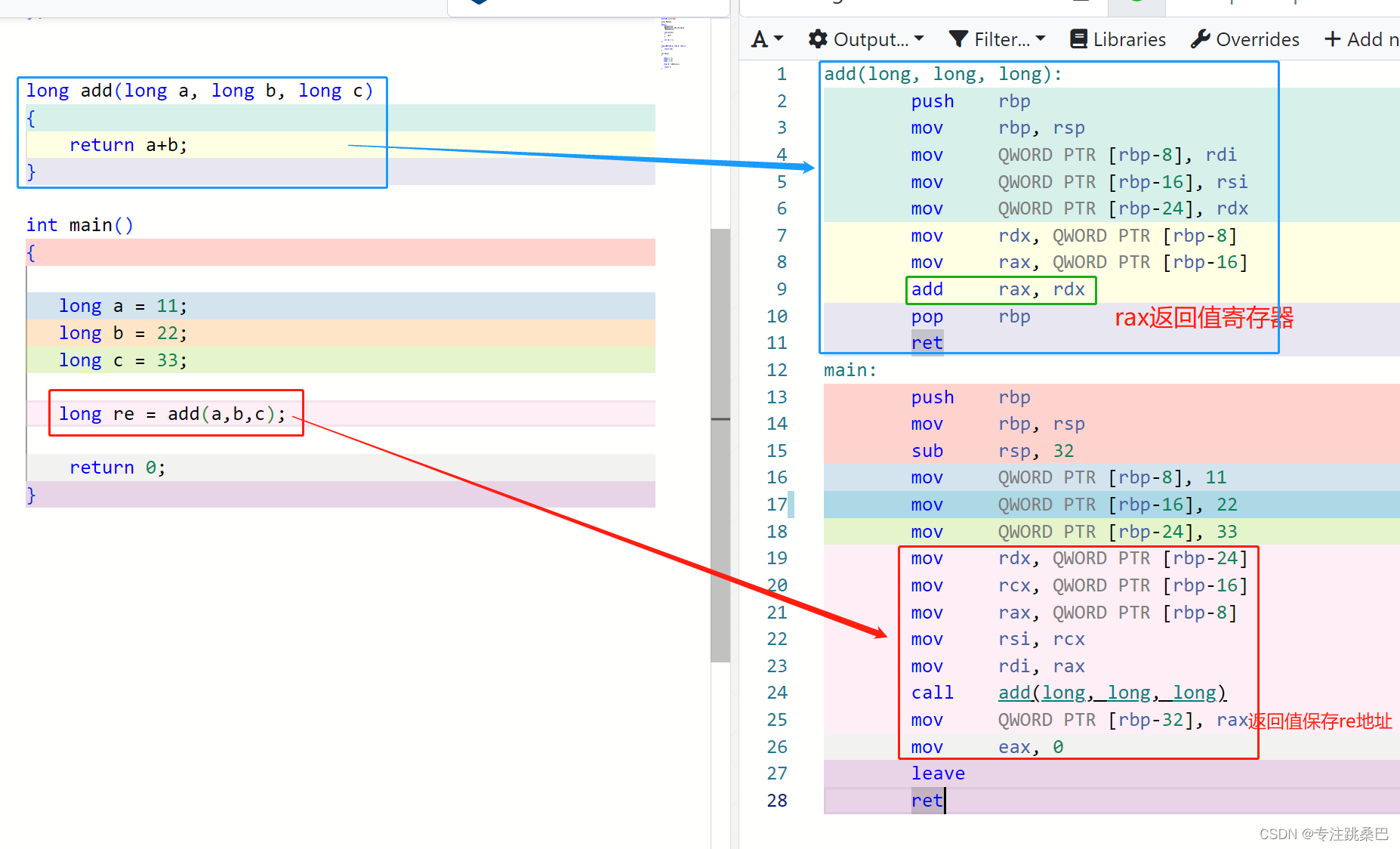
- 汇编 参数传递
- 顺序
- windows和linux不同
- 分析不同在哪里
- 参数传递顺序和函数中调用顺序及对应的栈使用
2、变量和this指针
变量
- 变量是
内存地址的别名 - 变量的类型决定了它占用内存空间的长度
- 全局变量、静态的地址是全局唯一的,但局部变量、临时变量是临时的
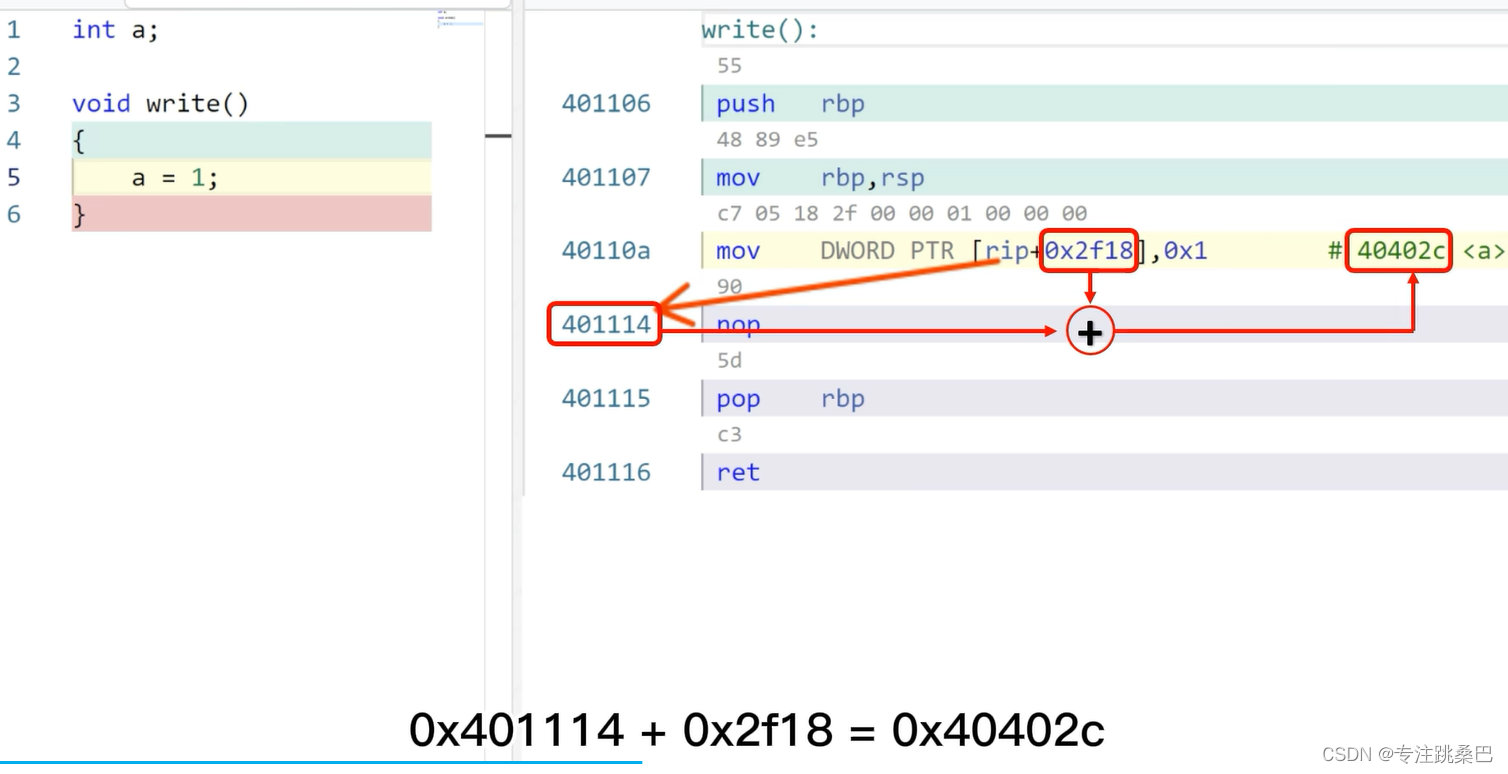
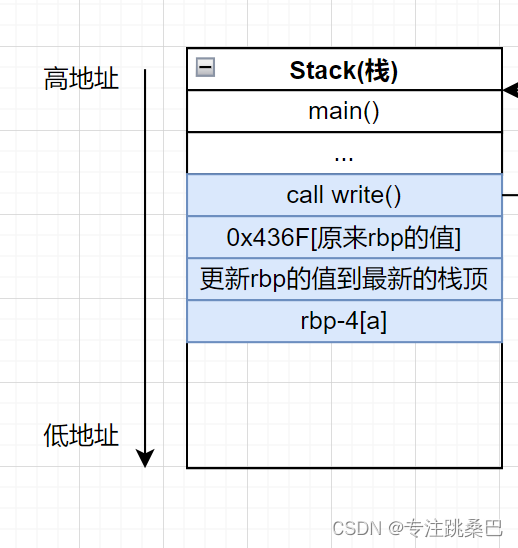
- 栈变量的生命周期及为什么临时变量的临时在哪里
- 临时变量过期后值是否会消失
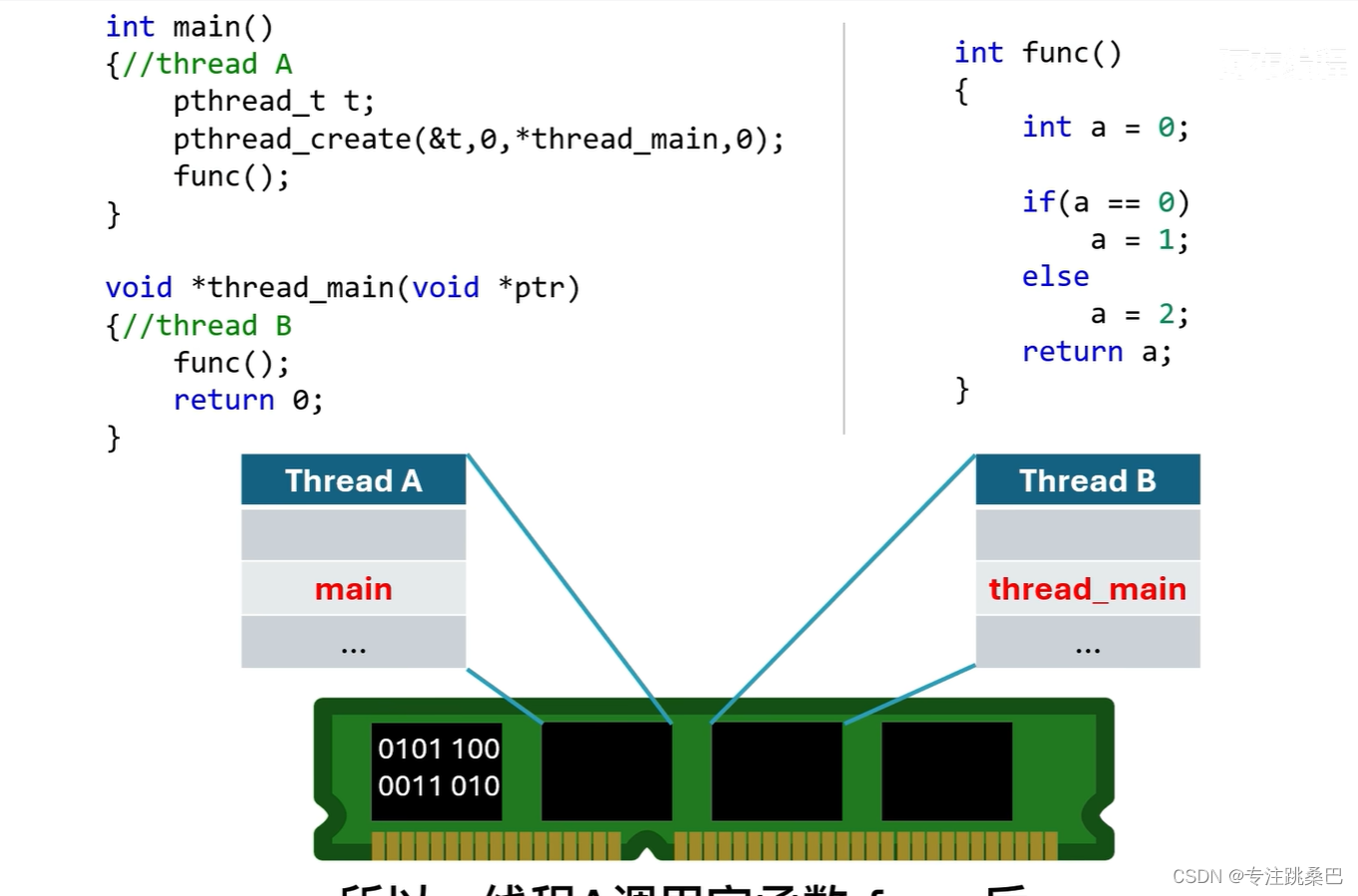
- 【🧨🧨🧨例】写个例子实际证明如add(x1)和add2(x1,y1)通过指针偏移可以再调用一次add2之后,下次调用add也能获得该值
- 为什么mvsc2019不行如何改
- 不同编译器的不同
this指针
this指针的本质就是作为默认参数传进函数,与普通函数本质上是一样的。
得到this指针后根据偏移获取对应成员变量或函数
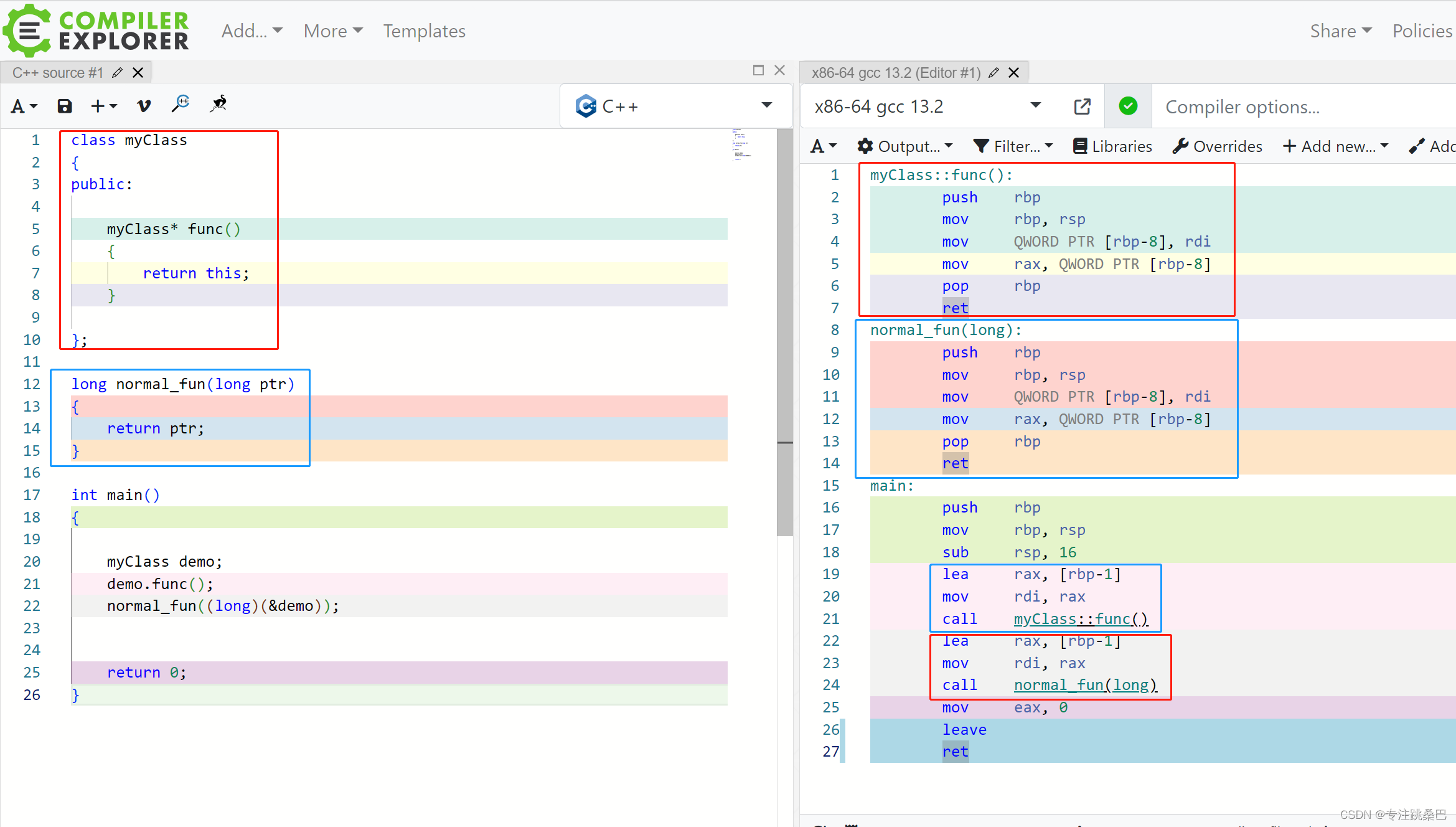
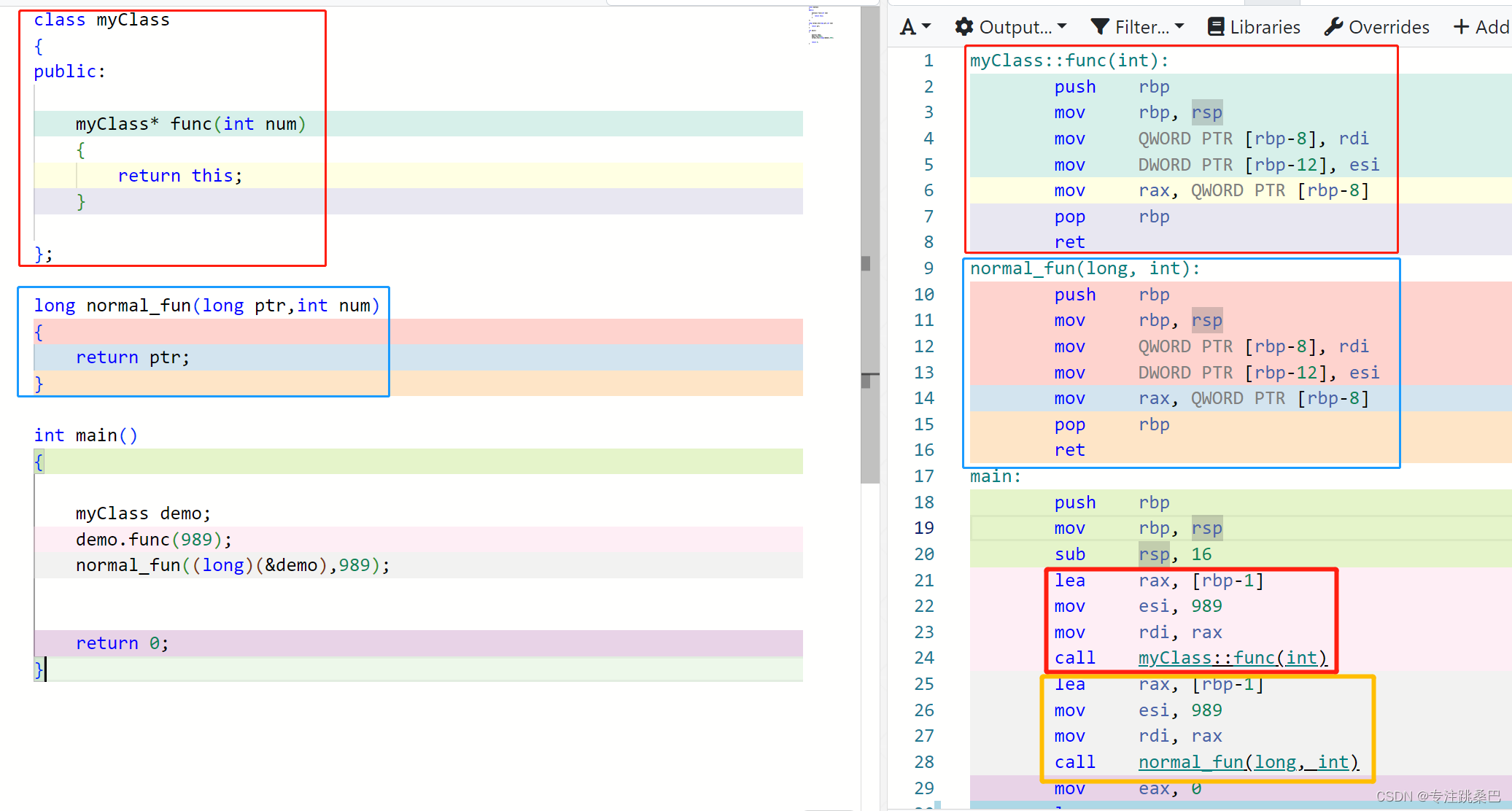
- 类中成员变量及this的内存分布【🧨🧨🧨例】举例说明,一个类中成员变量,类对象等内存分布情况
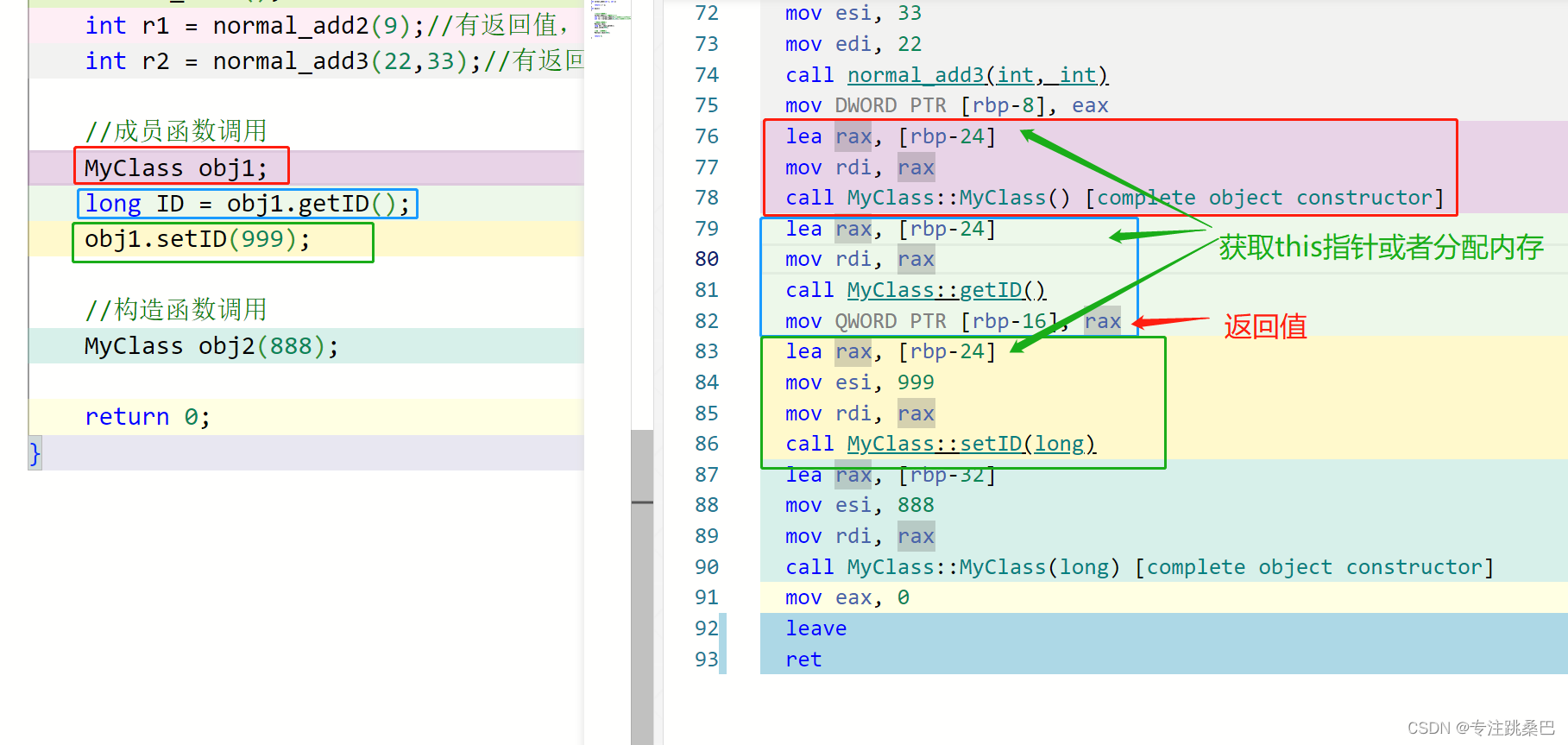
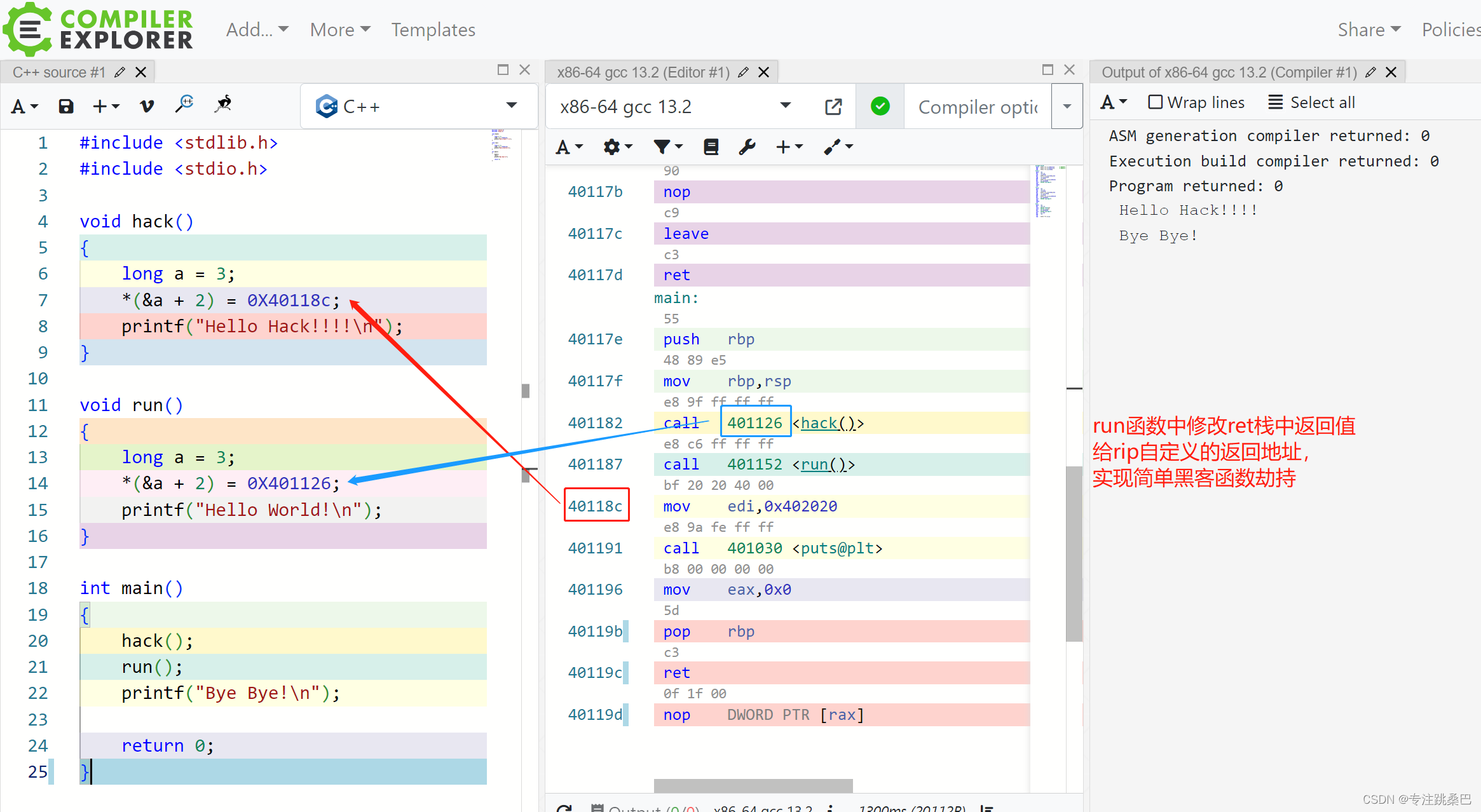
3、函数调用和构造函数
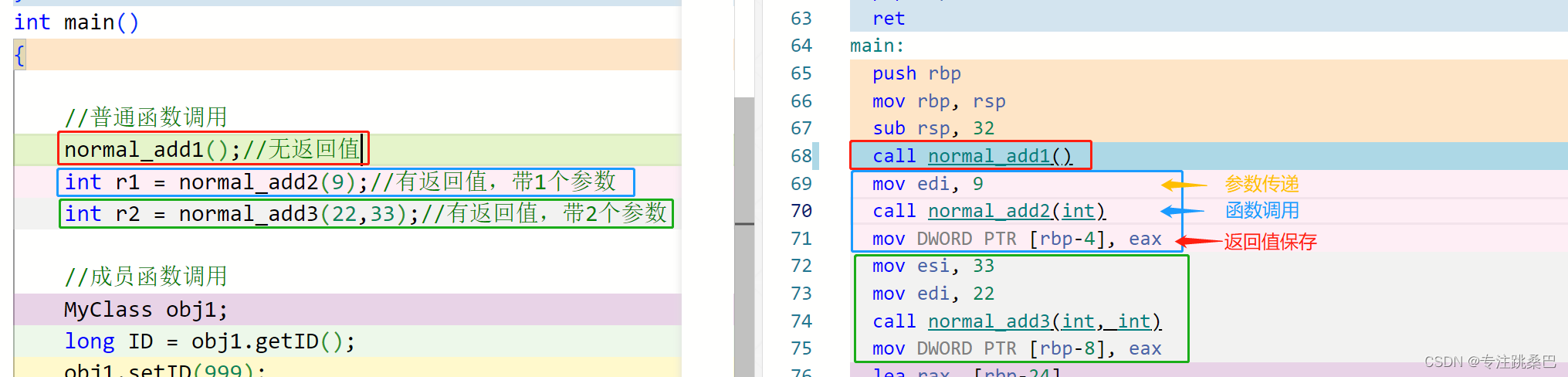
- 函数\构造函数 调用的原理
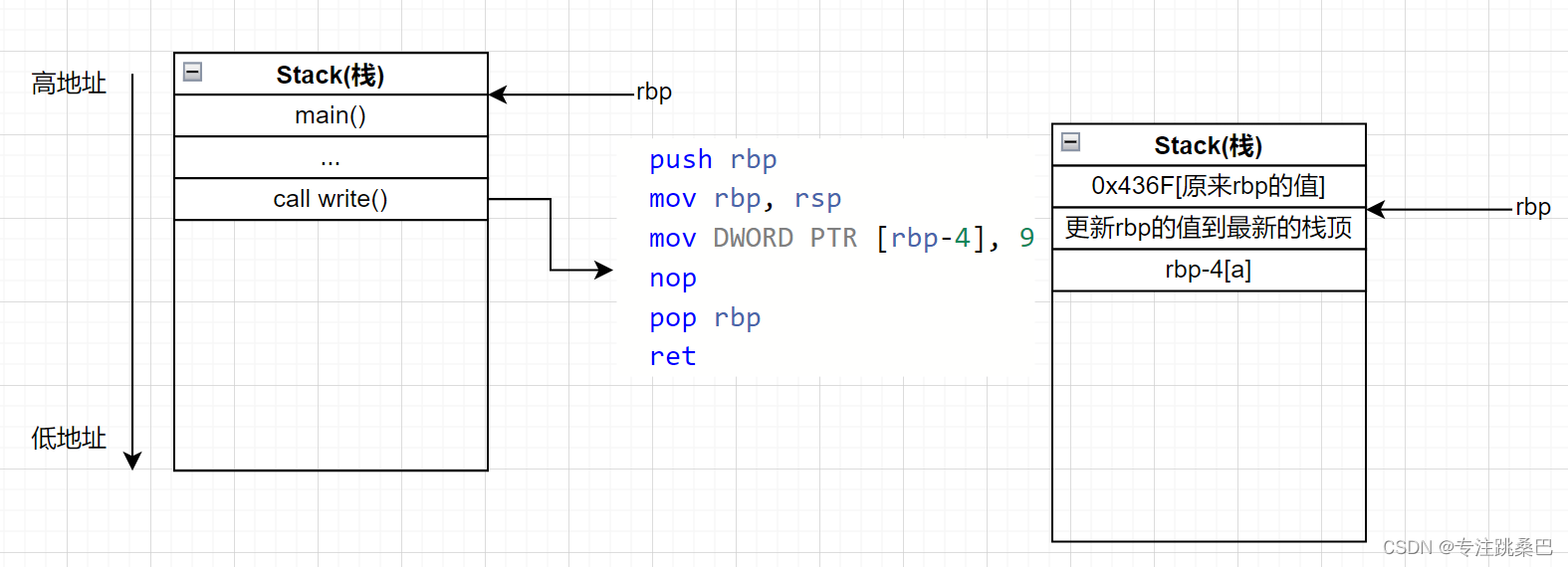
- rbp和rsp的理解
- rip的理解
- push、pop、ret指令的理解





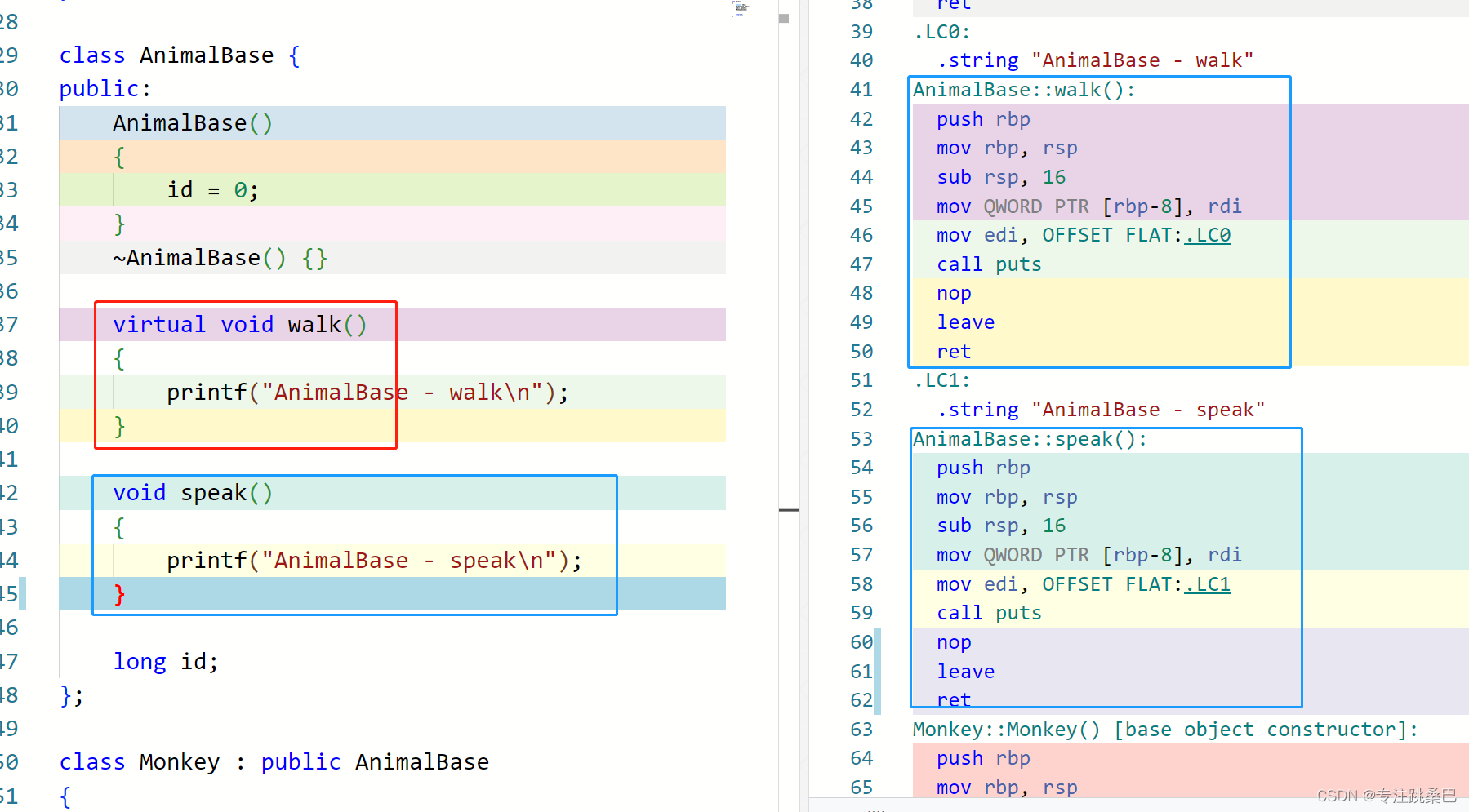
4、虚函数
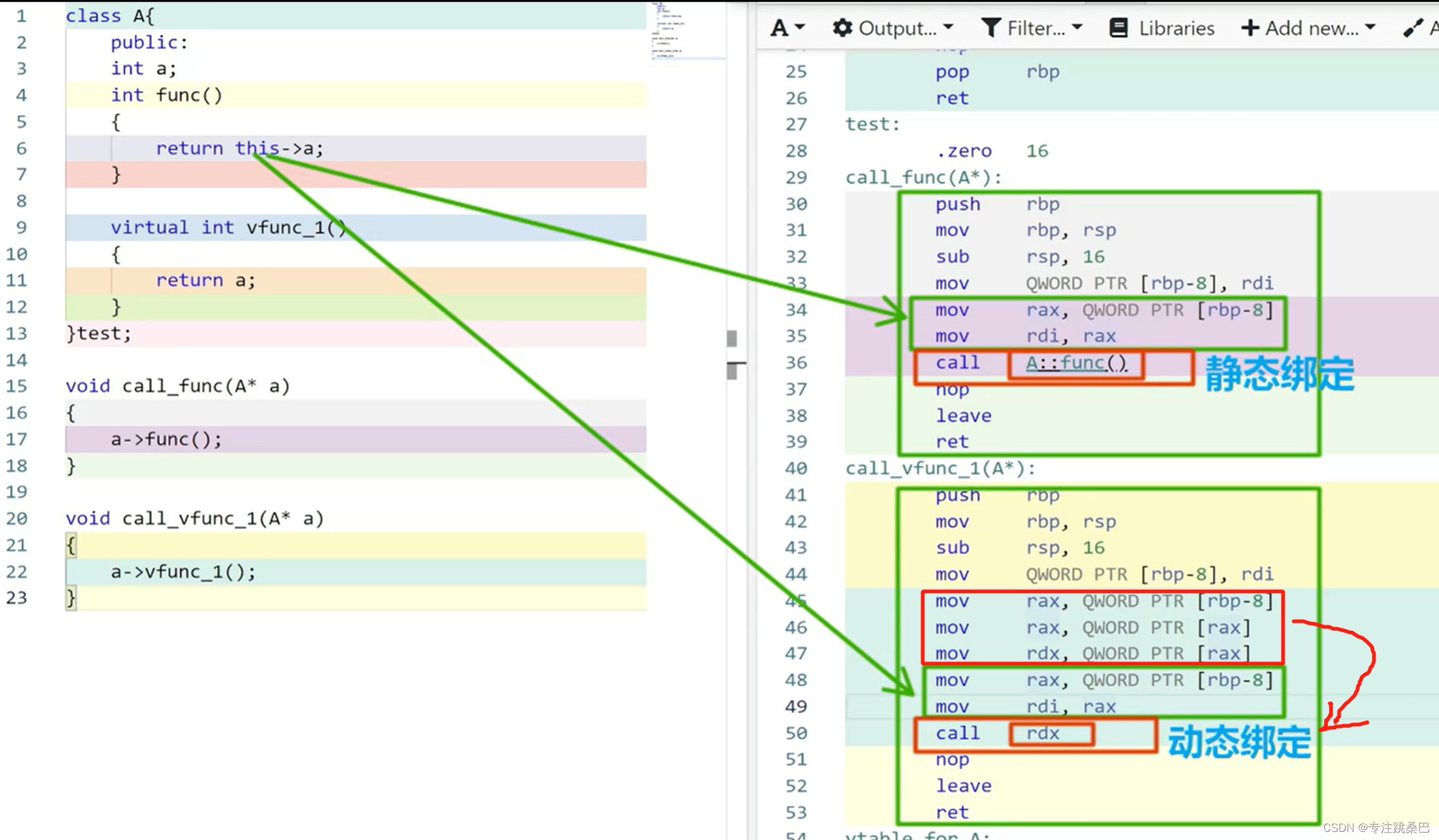
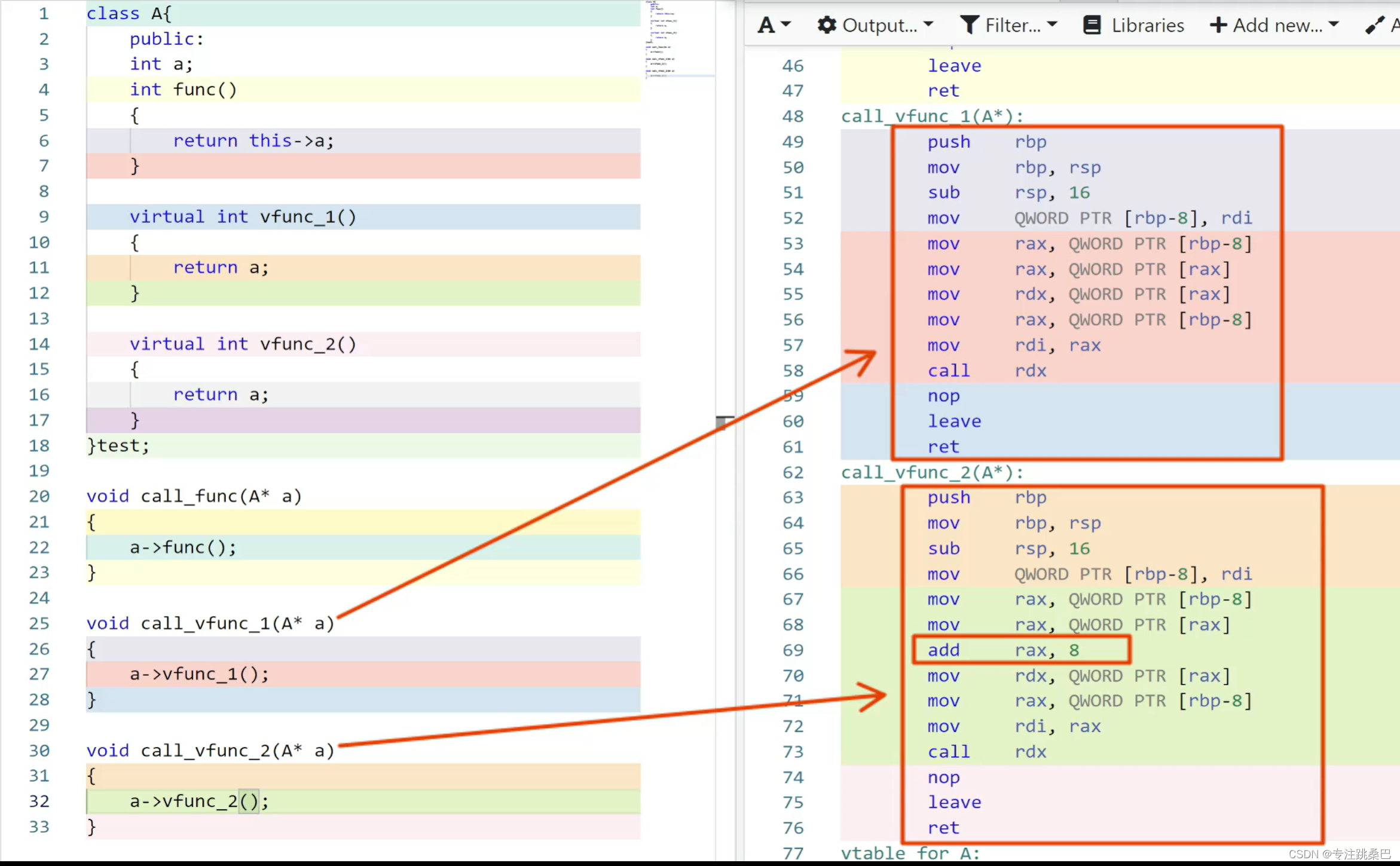
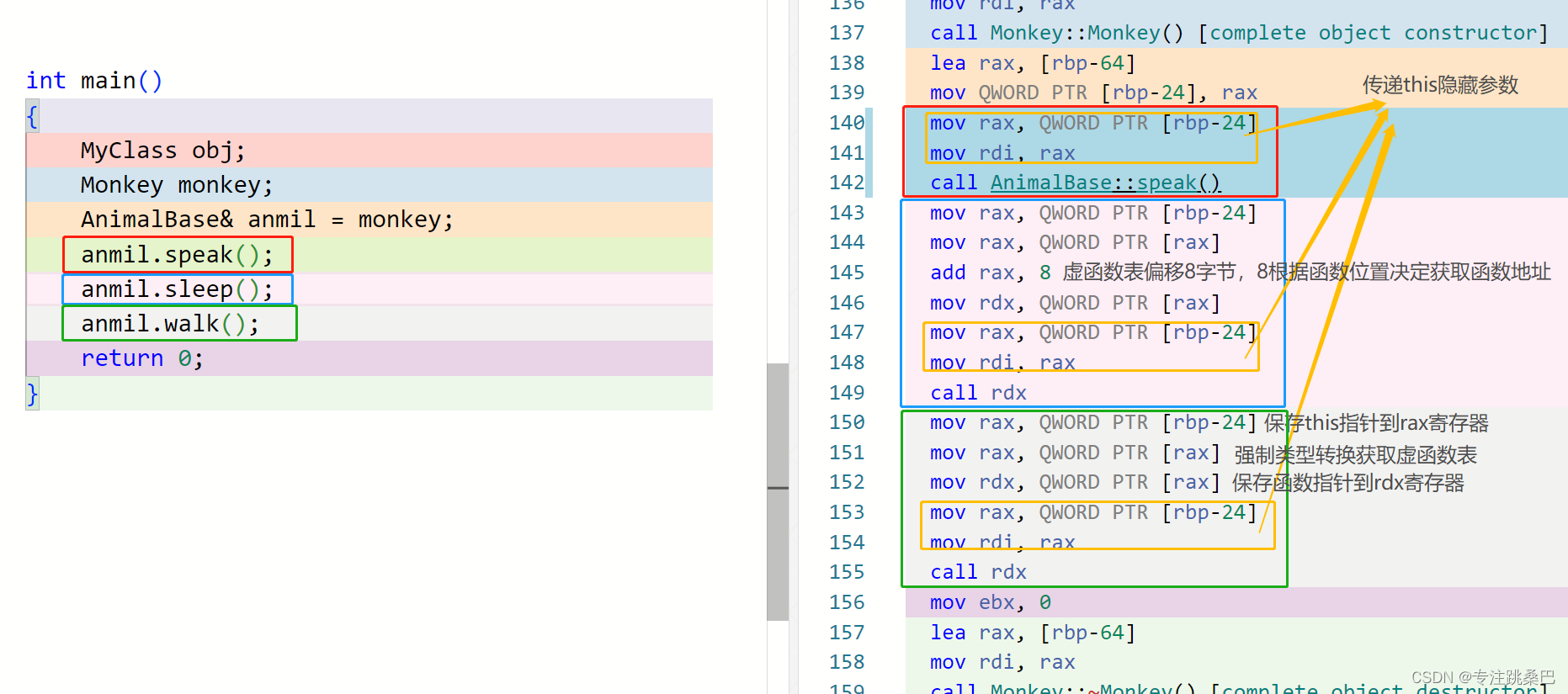
- 虚函数的实现和普通函数没有区别
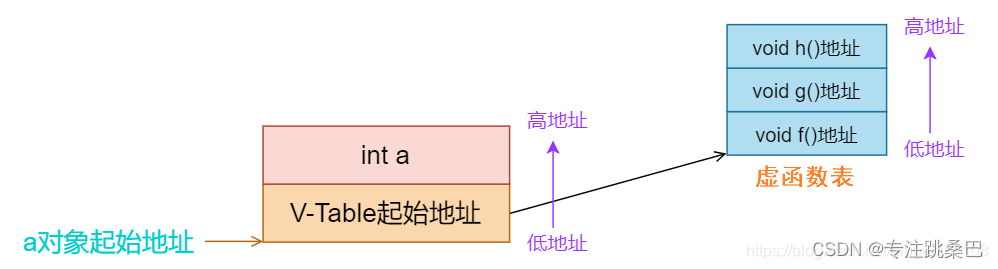
- 虚函数的调用借助隐藏变量vfptr[根据编译器]来完成
- 禁止在构造函数里面调用虚函数[为什么?如果非要调用呢]
- 虚函数表在构造阶段确定[过程学习]
- vfptr在构造函数阶段完成初始化,指向虚函数表的内存地址
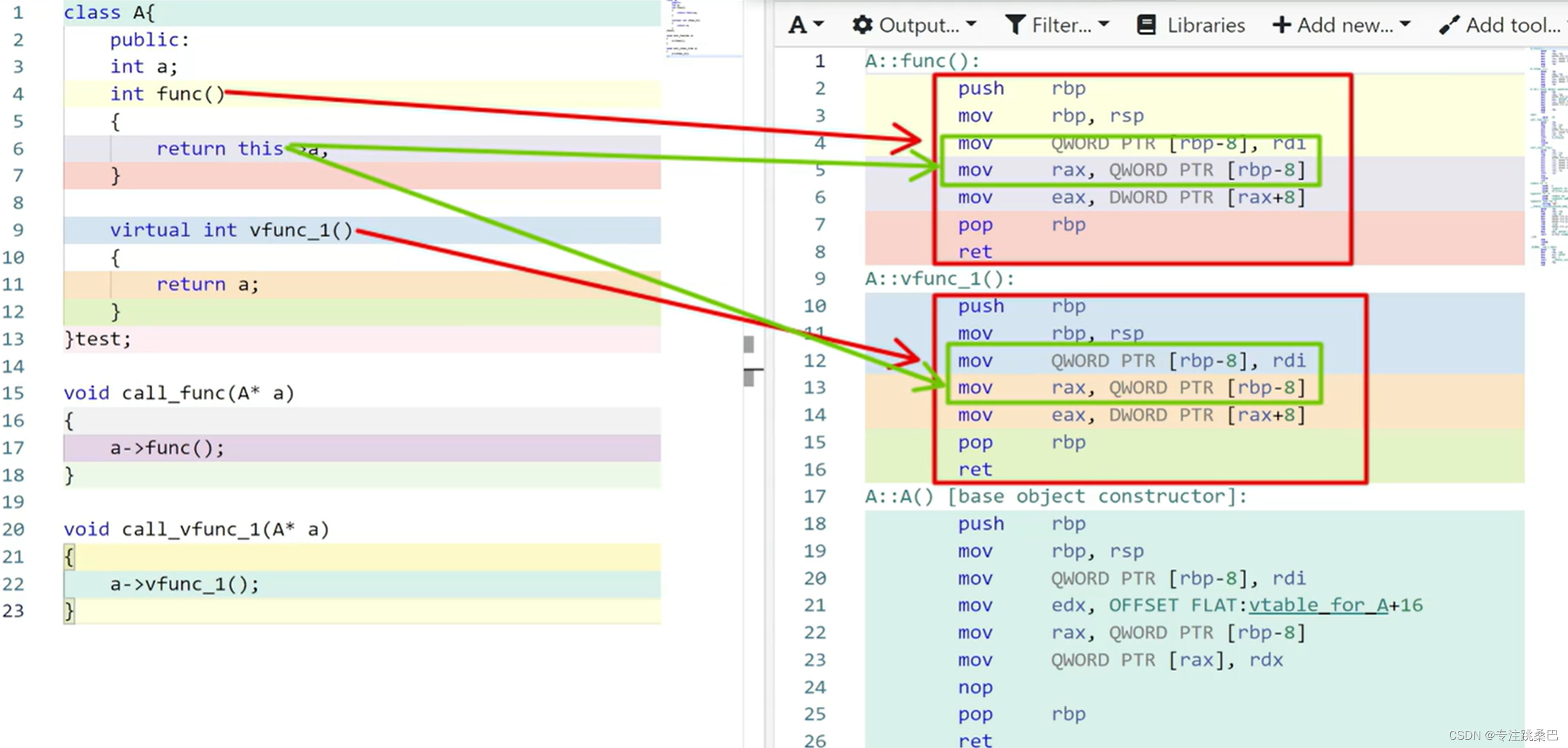


- 虚函数表哪里初始化?如何初始化,对应的汇编过程?
- 虚函数表初始化的时候为什么要偏移?
- 虚函数表如何输出
- [扩展]在父类的构造函数中调用多态函数会怎么样
- [扩展]不使用virtual,自己实现虚函数表来达到多态,动态绑定的效果
- struct 使用函数指针
- [🌻]struct 自己实现一遍虚函数表
typedef void (*FuncPointer)();FuncPointer* vtable = *(FuncPointer**)&obj;
//struct 使用函数指针成员变量来保存实现动态virtual
#include <iostream>
// 定义一个代表"动物"的结构体
struct Animal {
void (*speak)(void); // 函数指针,用于实现"speak"行为
};
// "Dog"和"Cat"的speak函数
void dog_speak() {
std::cout << "Woof!" << std::endl;
}
void cat_speak() {
std::cout << "Meow!" << std::endl;
}
// 创建一个动物并设置其"speak"函数
Animal* create_animal(void (*speak_func)(void)) {
Animal* new_animal = new Animal;
new_animal->speak = speak_func;
return new_animal;
}
// 让动物说话
void animal_speak(Animal* animal) {
animal->speak();
}
int main() {
// 创建一个狗和一个猫
Animal* dog = create_animal(dog_speak);
Animal* cat = create_animal(cat_speak);
// 让它们各自说话
animal_speak(dog);
animal_speak(cat);
// 清理
delete dog;
delete cat;
return 0;
}
//struct 自己实现一遍虚函数表#include <stdlib.h>
#include <stdio.h>
// 定义一个代表"动物"的结构体
struct Animal;
typedef void(*FUN)(Animal*);
struct Animal {
FUN* V;
long id;
};
void dog_speak(Animal* dog) {printf("汪汪汪 id = %d\n",dog->id);}
void dog_walk(Animal* dog) { printf("哐哐哐 id = %d\n", dog->id); }
FUN Dog__vftable[] =
{
dog_speak,
dog_walk
};
void cat_speak(Animal* cat) { printf("喵喵喵 id = %d\n", cat->id); }
void cat_walk(Animal* cat) { printf("鸟鸟鸟 id = %d\n", cat->id); }
FUN Cat__vftable[] =
{
cat_speak,
cat_walk
};
void animal_speak(Animal* animal)
{
animal->V[0](animal);
}
void animal_walk(Animal* animal)
{
animal->V[1](animal);
}
int main() {
//创建一个狗
Animal* dog = new Animal();
dog->id = 0; //初始化成员变量
dog->V = Dog__vftable; //初始化虚函数表
//创建一个猫
Animal* cat = new Animal();
cat->id = 1; //初始化成员变量
cat->V = Cat__vftable; //初始化虚函数表
// 让它们各自说话
animal_speak(dog);
animal_speak(cat);
//让它们各自走路
animal_walk(dog);
animal_walk(cat);
// 清理
delete dog;
delete cat;
return 0;
}
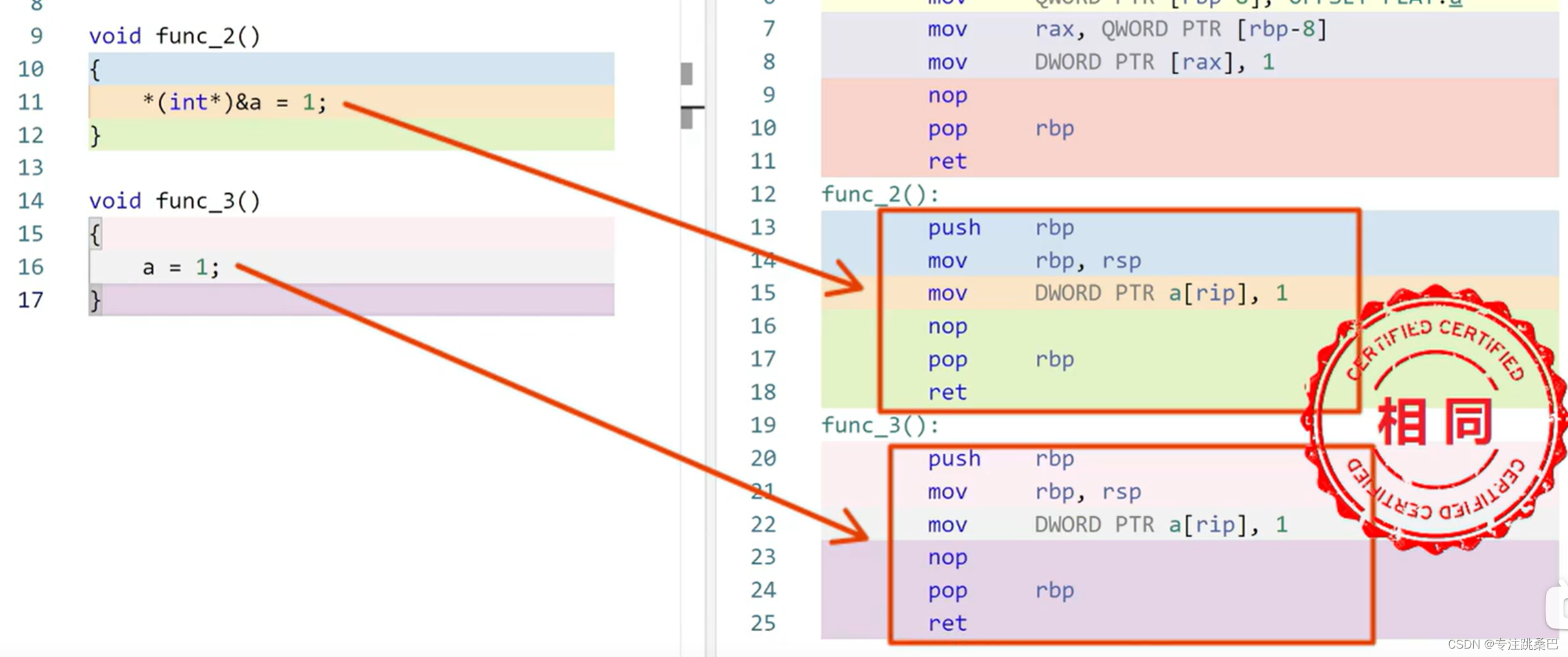
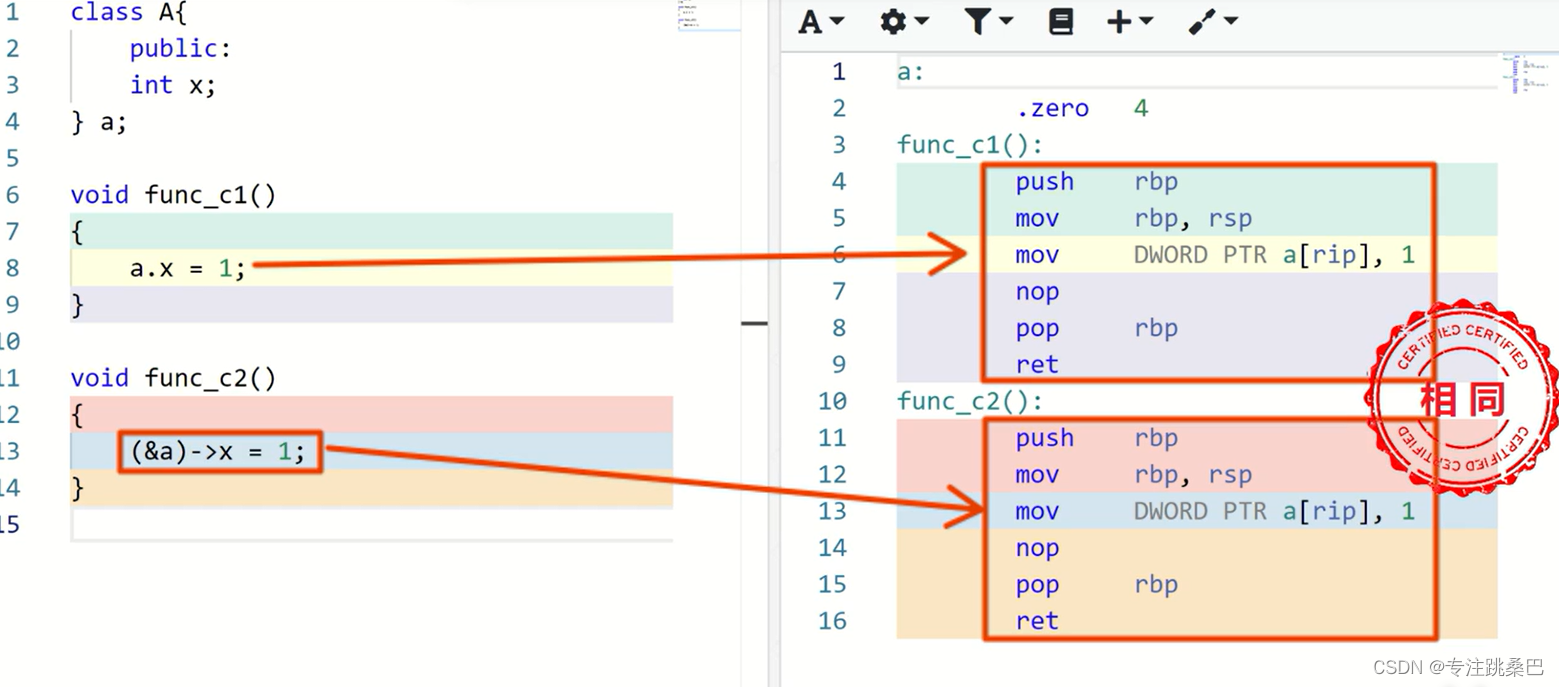
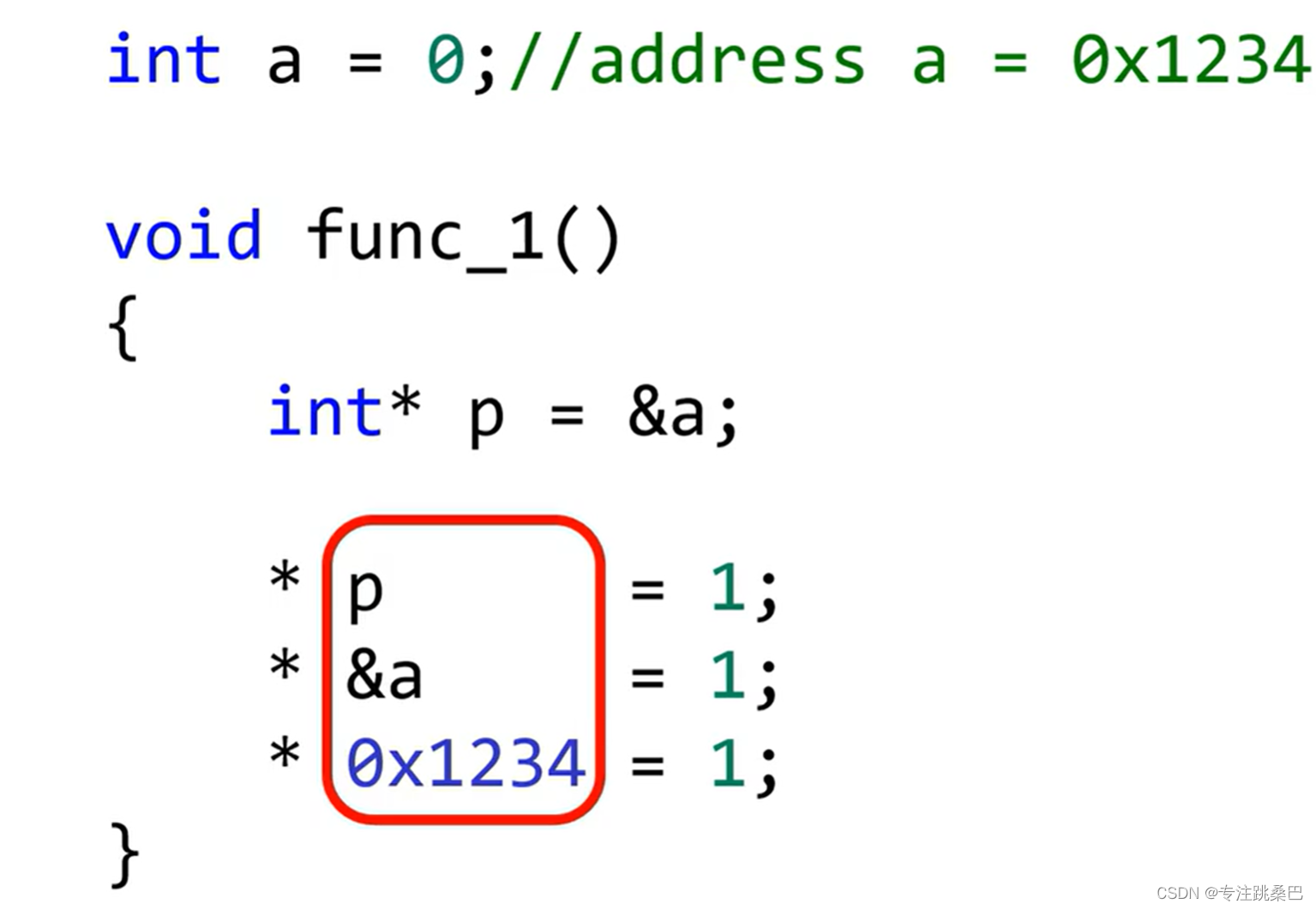
5、指针和变量
- 共性
- 就变量读写而言,指针和变量是没有区别的【变量大小可能不同,指针变量大小都一样,因为放的都是地址】
- 变量是内存地址的别名
- *操作,解引用。最基本的变量读写等同于地址*号操作
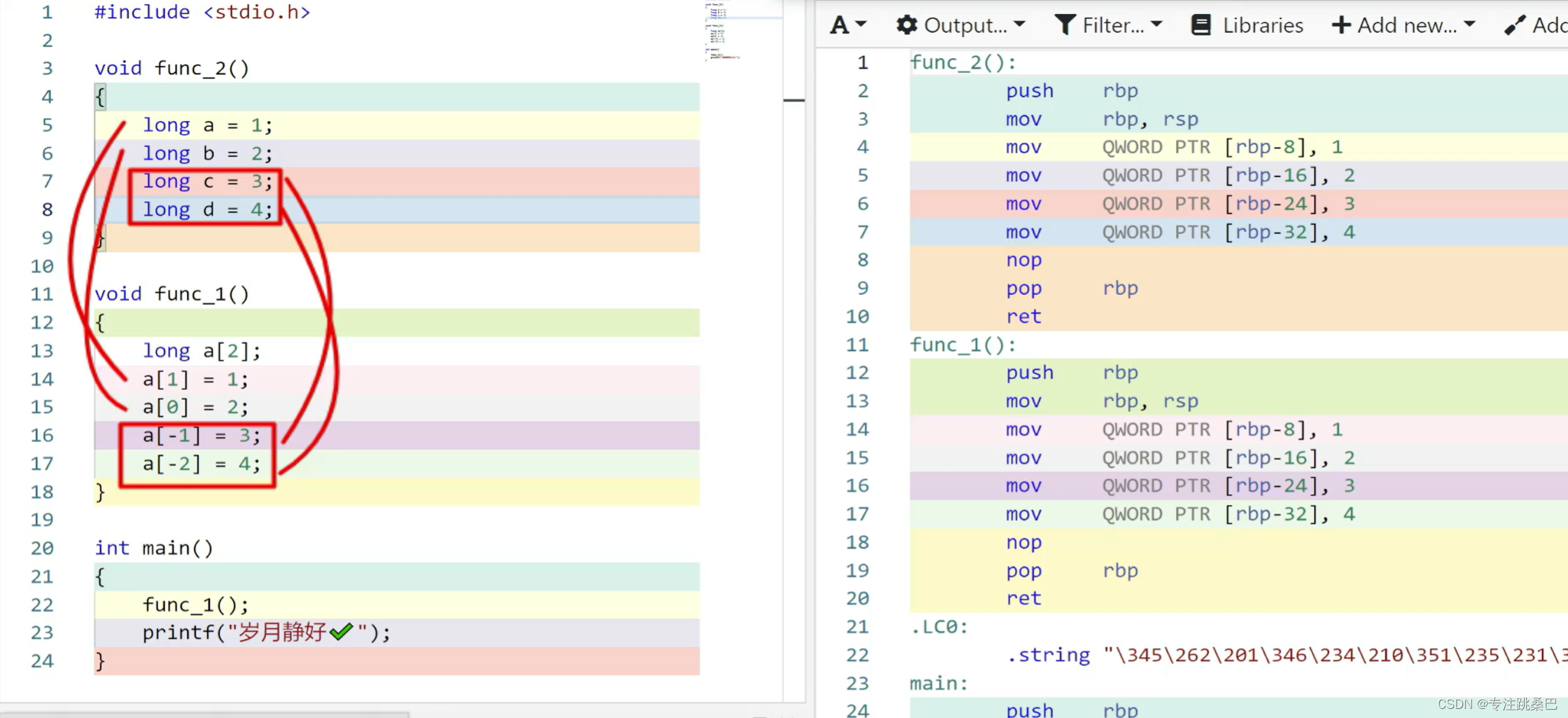
- 指针偏移如+1,偏移多少是根据指针的类型来偏移,如char只偏移1,long偏移4,如果是类偏移是类的大小

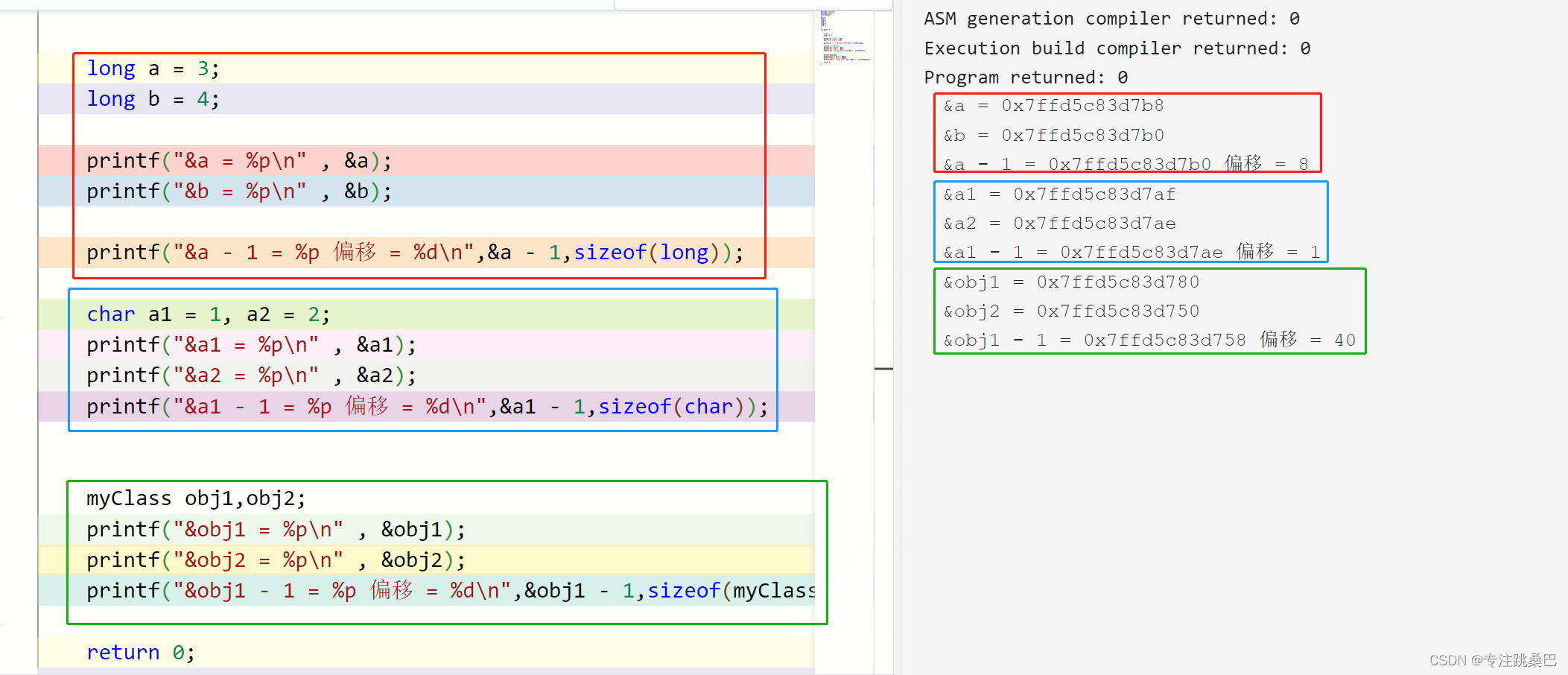
//指针偏移#include <stdlib.h>
#include <stdio.h>
class myClass
{
public:
long a;
long b;
long c;
long d;
long e;
};
int main() {
long a = 3;
long b = 4;
printf("&a = %p\n" , &a);
printf("&b = %p\n" , &b);
printf("&a - 1 = %p 偏移 = %d\n",&a - 1,sizeof(long));
char a1 = 1, a2 = 2;
printf("&a1 = %p\n" , &a1);
printf("&a2 = %p\n" , &a2);
printf("&a1 - 1 = %p 偏移 = %d\n",&a1 - 1,sizeof(char));
myClass obj1,obj2;
printf("&obj1 = %p\n" , &obj1);
printf("&obj2 = %p\n" , &obj2);
printf("&obj1 - 1 = %p 偏移 = %d\n",&obj1 - 1,sizeof(myClass));
return 0;
}
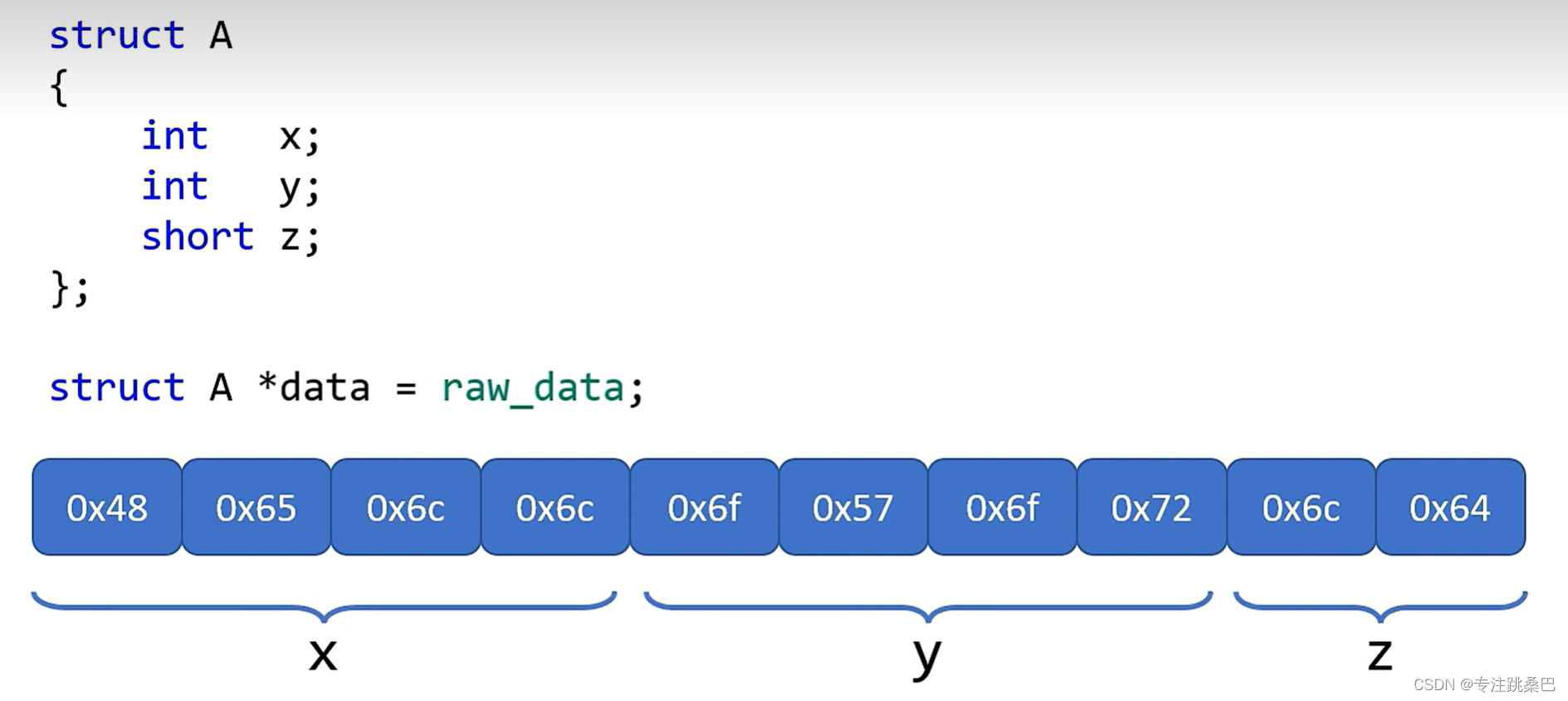


可以无代价变化成任意数据结构方便使用
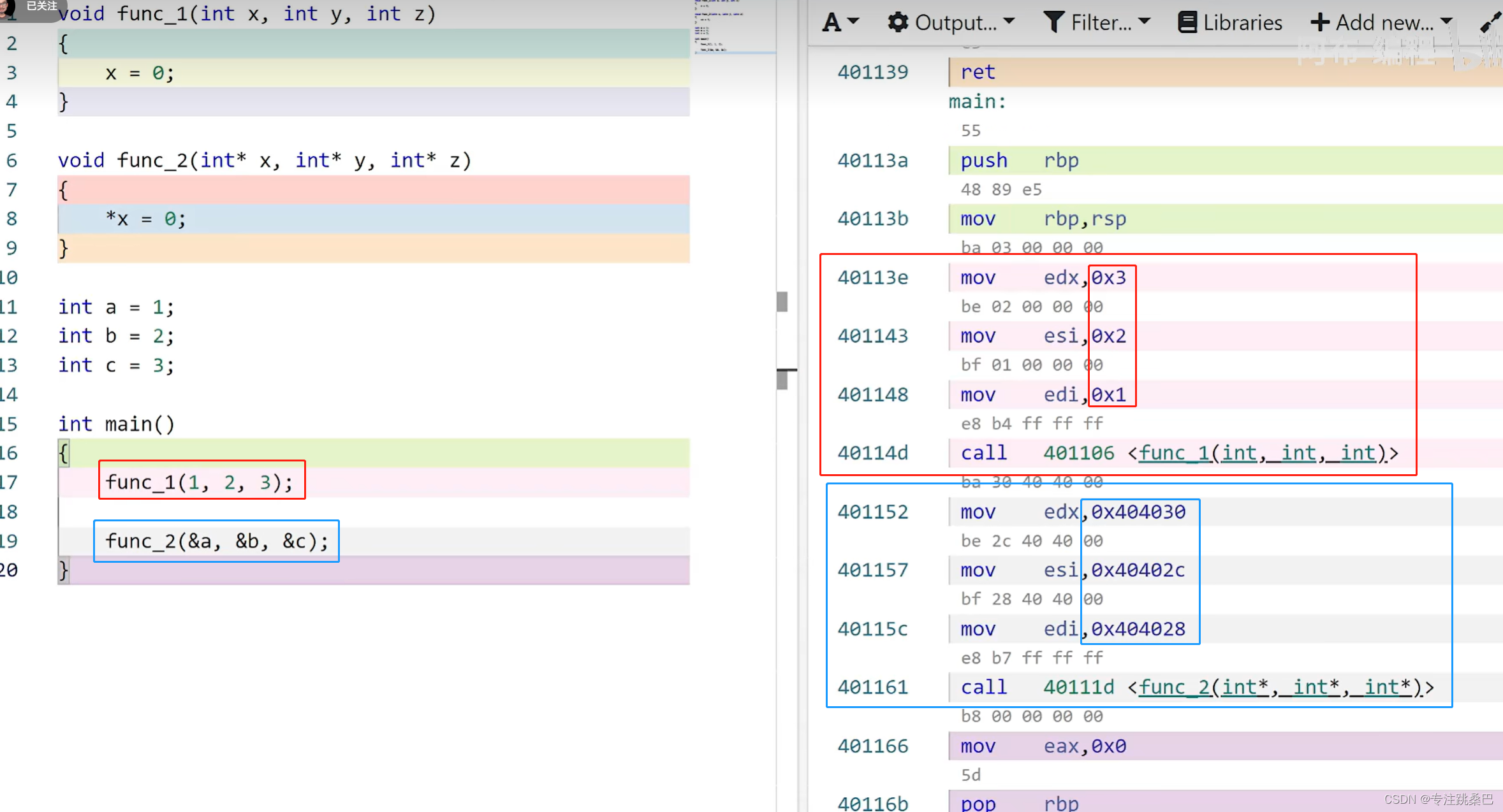
6、传值、传引用、传指针区别
- 传递参数就是给寄存器赋值。所以在CPU眼里,没有形参和实参的概念,也没有传指针和值的概念
- 传递值就是复制到临时寄存器里面。【举例说明过程】传递引用和指针没有区别,从CPU角度看

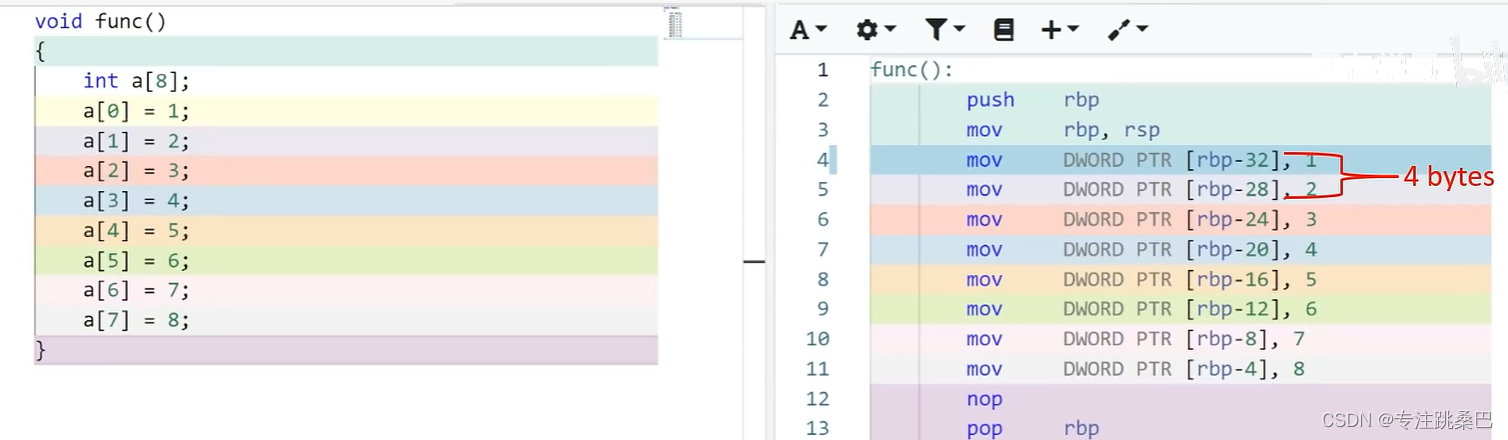
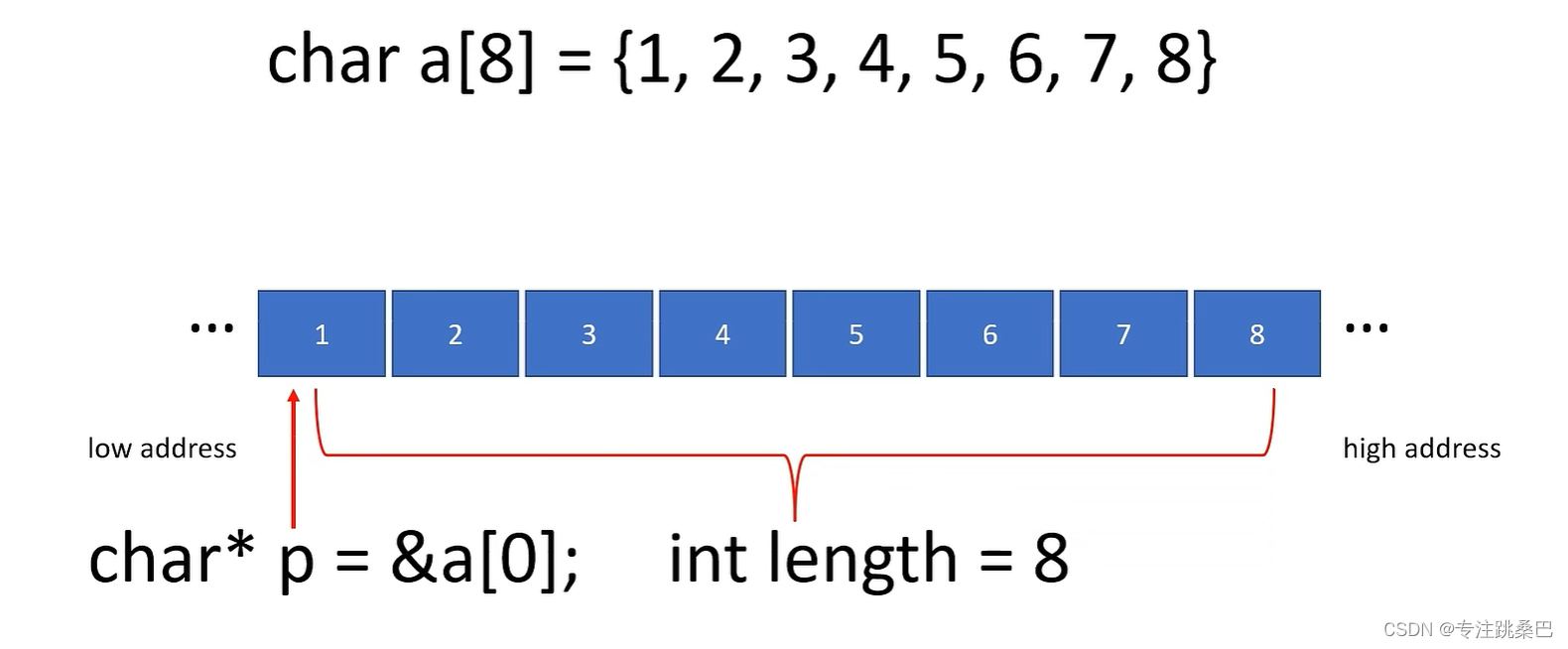
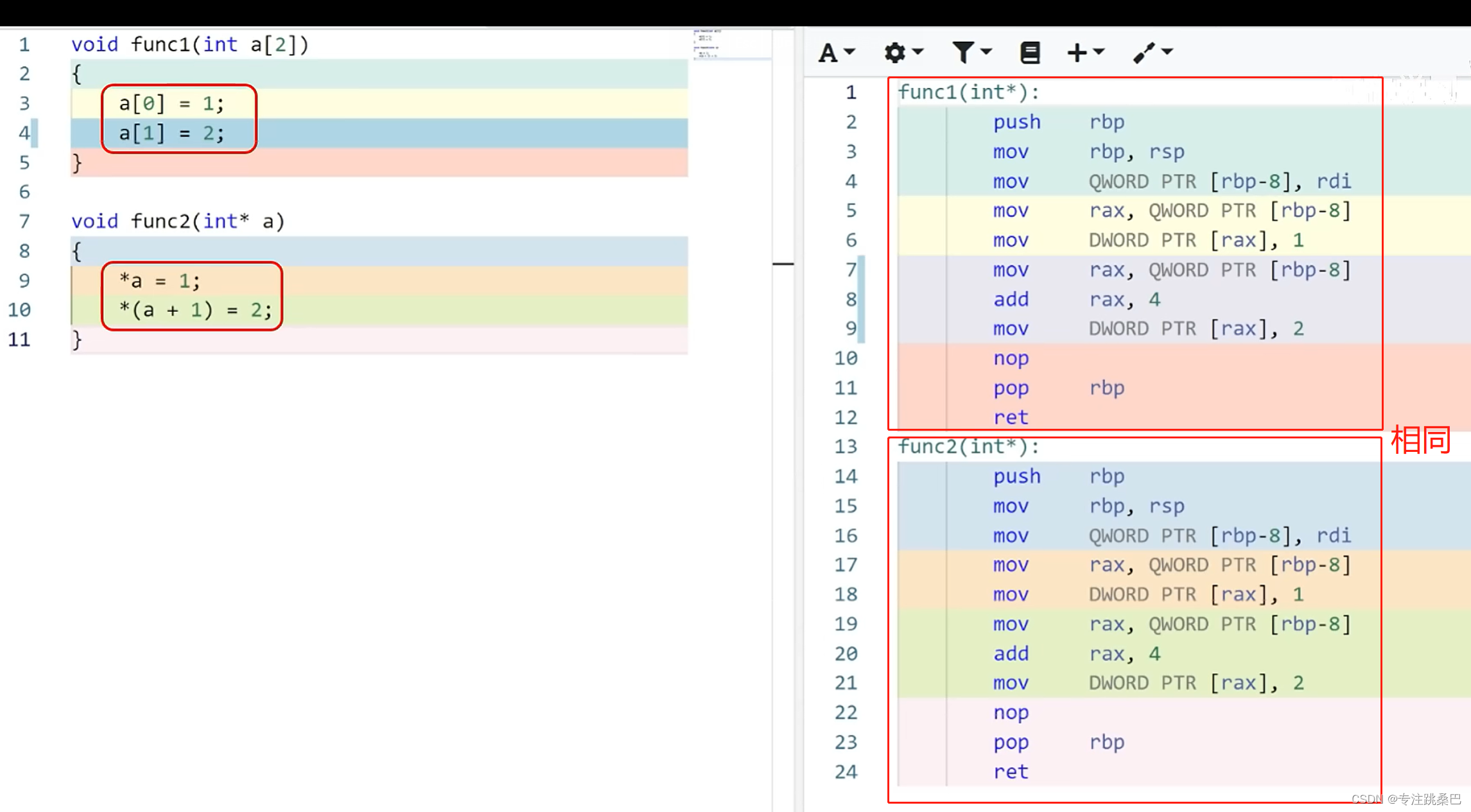
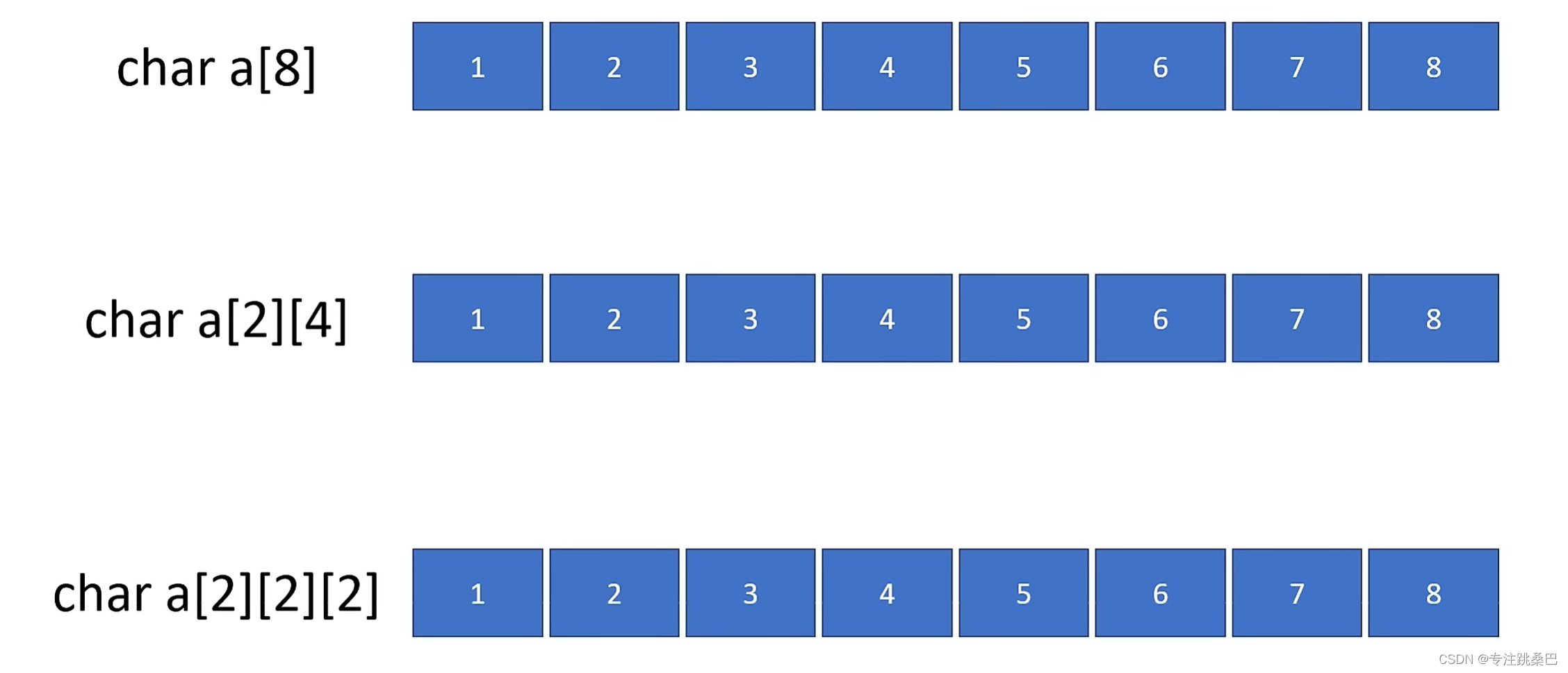
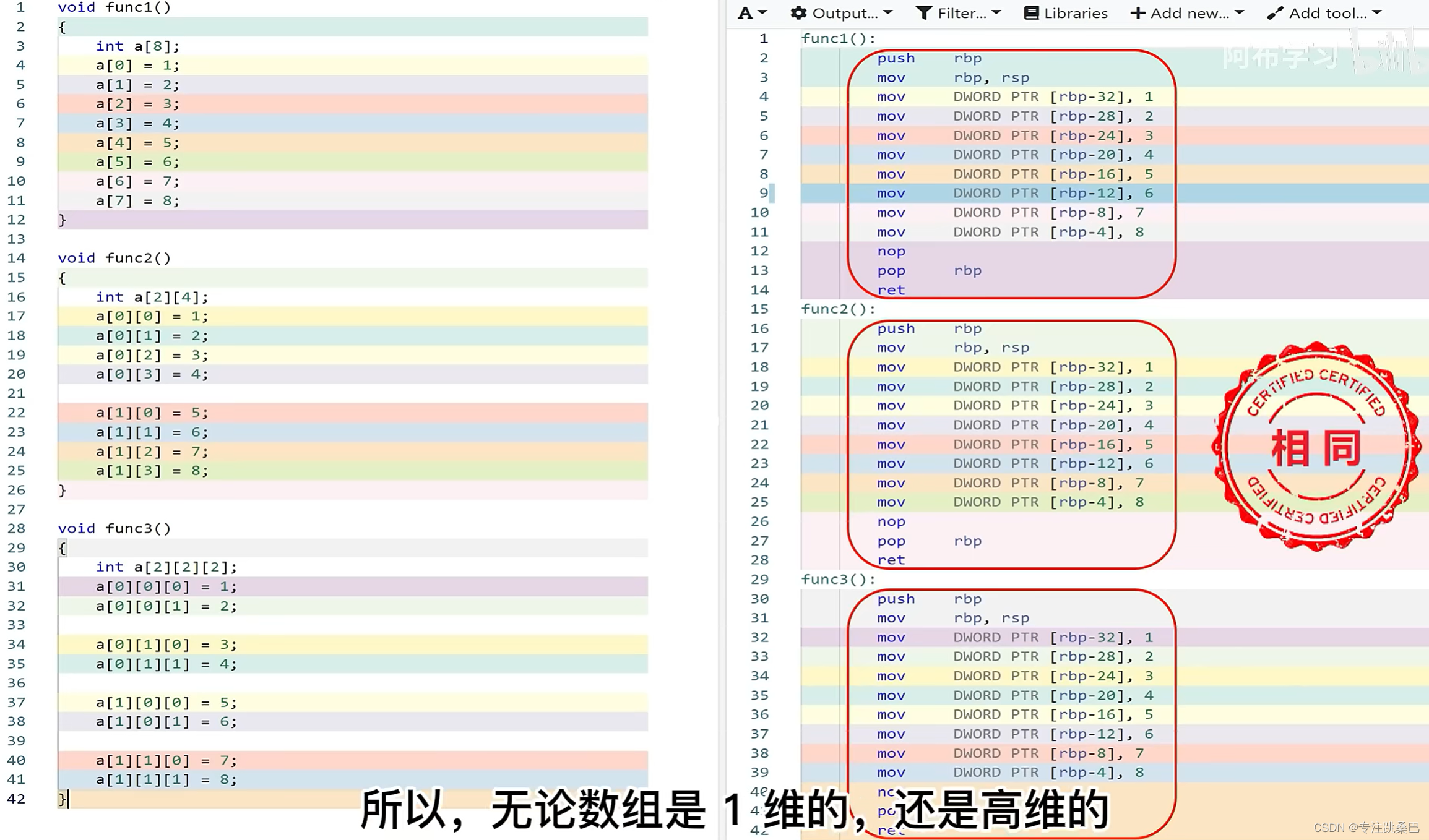
7、数组和数组指针
- 数组和数组指针,从汇编角度来看本质上一回事
- 在C++中,数组名(如
a)和数组的第一个元素的地址(如&a[0])看似相似,但实际上有一些重要的区别。
数组名 a
a本身不是一个变量,不能被赋予新的地址值。- 在大多数情况下,数组名
a会被隐式转换为指向数组第一个元素的指针。因此,a和&a[0]在这方面表现得很相似。 - 使用
sizeof(a)会返回整个数组的大小(字节),不是单个元素的大小。在这个例子里,如果int是4字节,sizeof(a)将返回4 * 3 = 12。 a有数组类型(在这个例子中是int[3]),这有时可以在类型推导(如模板元编程)中用到。
指针 &a[0]
&a[0]是一个指针,具体来说是一个int*类型的指针,指向数组的第一个元素。- 你可以有多个这样的指针,而且这些指针是可以修改的(你可以让它们指向其他地址)。
- 使用
sizeof(&a[0])会返回指针的大小,而不是整个数组的大小。 &a[0]的类型是int*,没有包含数组大小或其他额外信息。
示例
#include<iostream>using namespace std;
int main() {
int a[3] = { 1, 2, 3 };
int* p = &a[0];
std::cout << *p << std::endl; // 输出1,解引用第一个元素
std::cout << *(a) << std::endl; // 输出1,因为 a 隐式转换为指向第一个元素的指针
std::cout << sizeof(a) << " size = " << sizeof(a) /sizeof(a[0]) << std::endl; // 输出数组的总大小(字节)
std::cout << sizeof(p) << std::endl; // 输出指针的大小(字节)
}
简而言之,数组名更多地像是一个代表整个数组块内存的符号,而数组的第一个元素的地址更像是一个普通的指针,没有包含数组的其他信息。


8、malloc和new
- 栈和堆的区别
- 栈速度块
- 栈是临时的,每个线程有自己的栈。多线程可以访问堆,堆一个进程只有一个
- 堆多次使用后会产生内存碎片
- malloc是最基本的申请空间,可以简单理解为单纯的函数调用
- new的话会自动调用构造函数,可以理解为malloc+构造
- free和delete类似
- malloc 和 new 都是可以被重载的

#include <stdlib.h>#include <stdio.h>
class MyClass
{
public:
MyClass()
{
x = 1;
y = 2;
}
~MyClass()
{
}
long x;
long y;
};
void func_new()
{
MyClass* obj = new MyClass();
}
void func_malloc()
{
malloc(4);
}
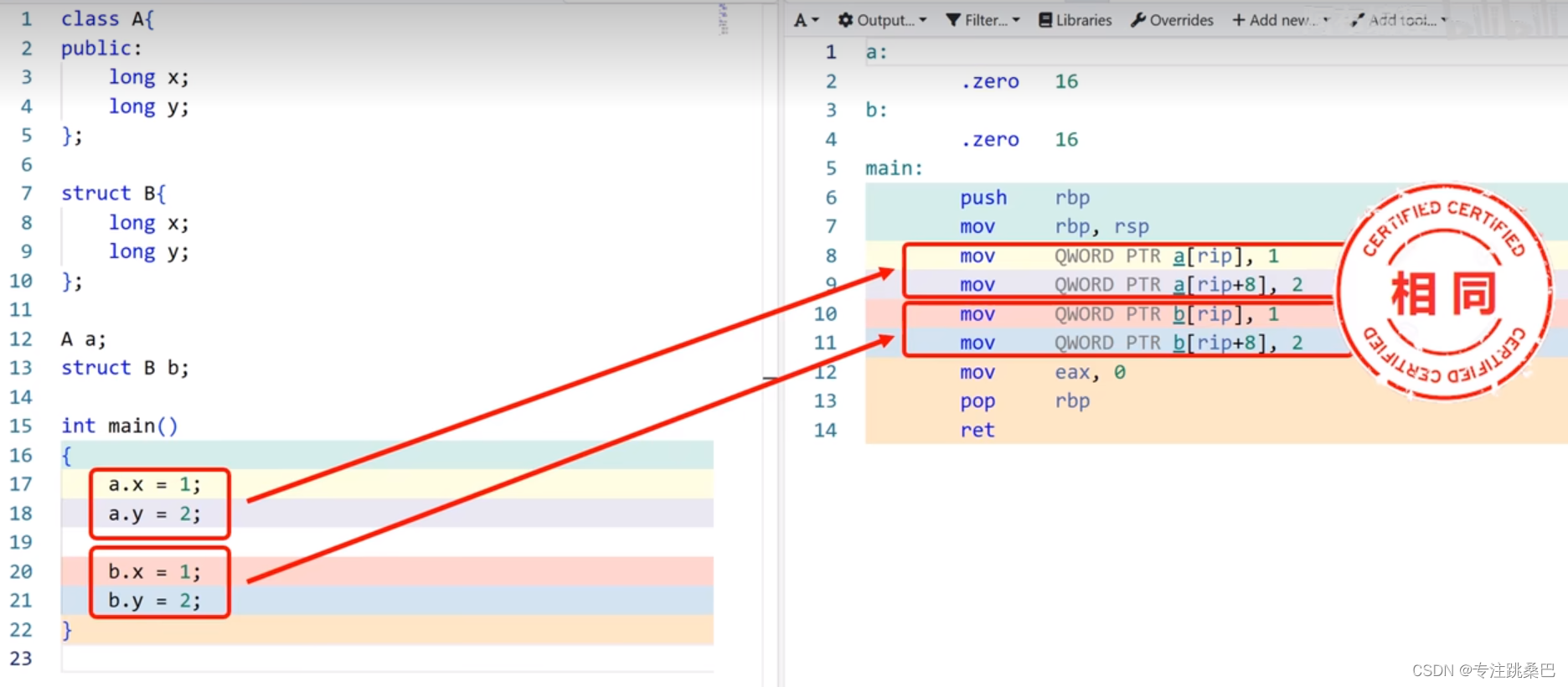
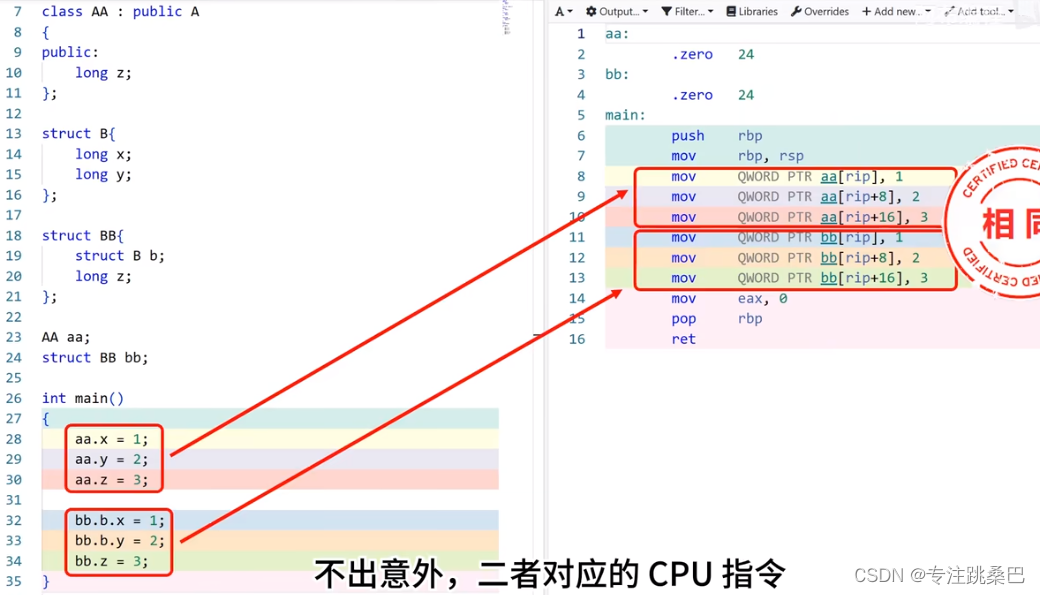
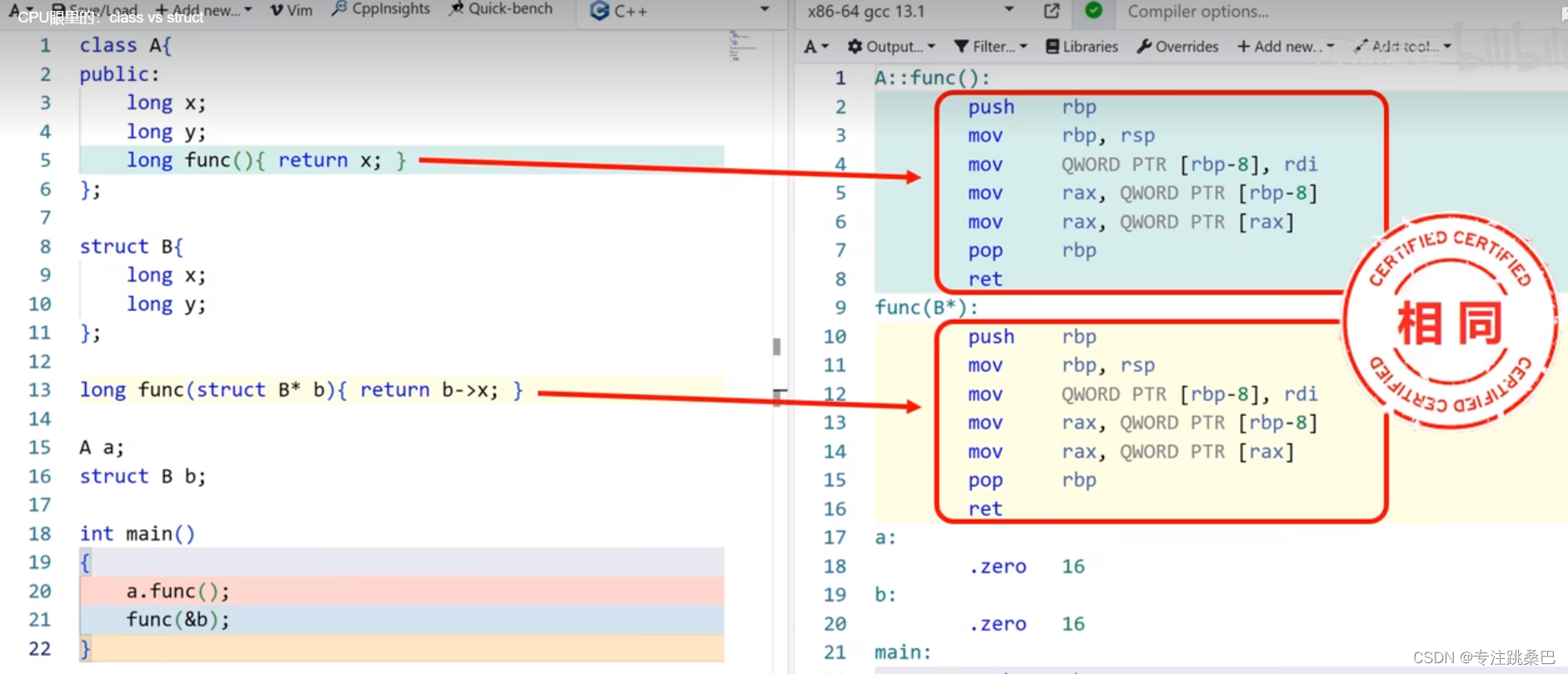
9、class和struct
- struct 无法有成员函数
- struct实现 封装、多态、继承[设计模式]
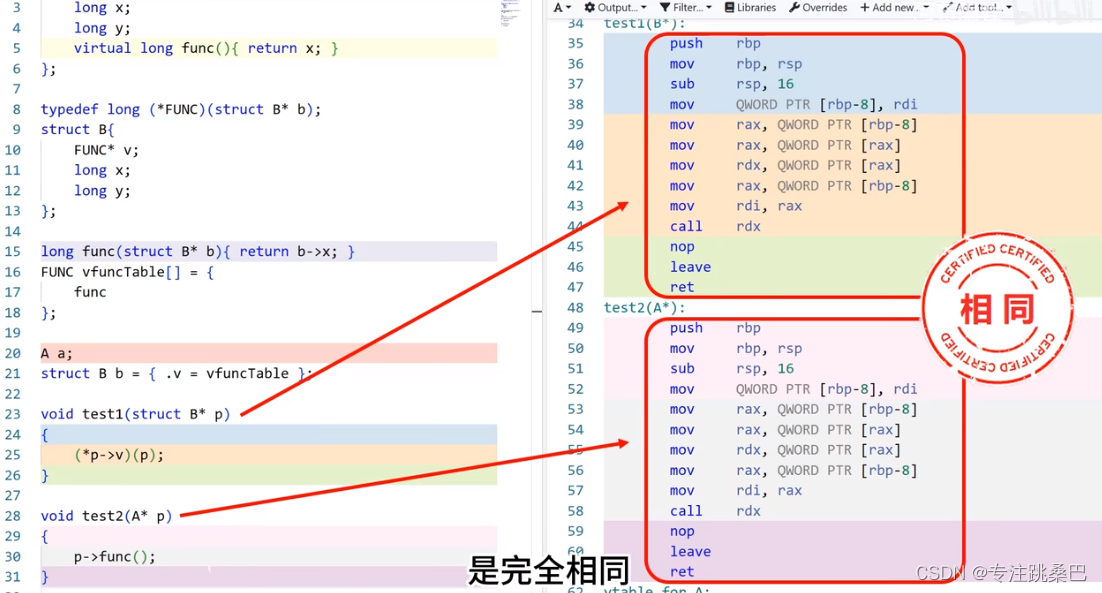
10、析构函数
- 为什么多态需要析构函数+virtual
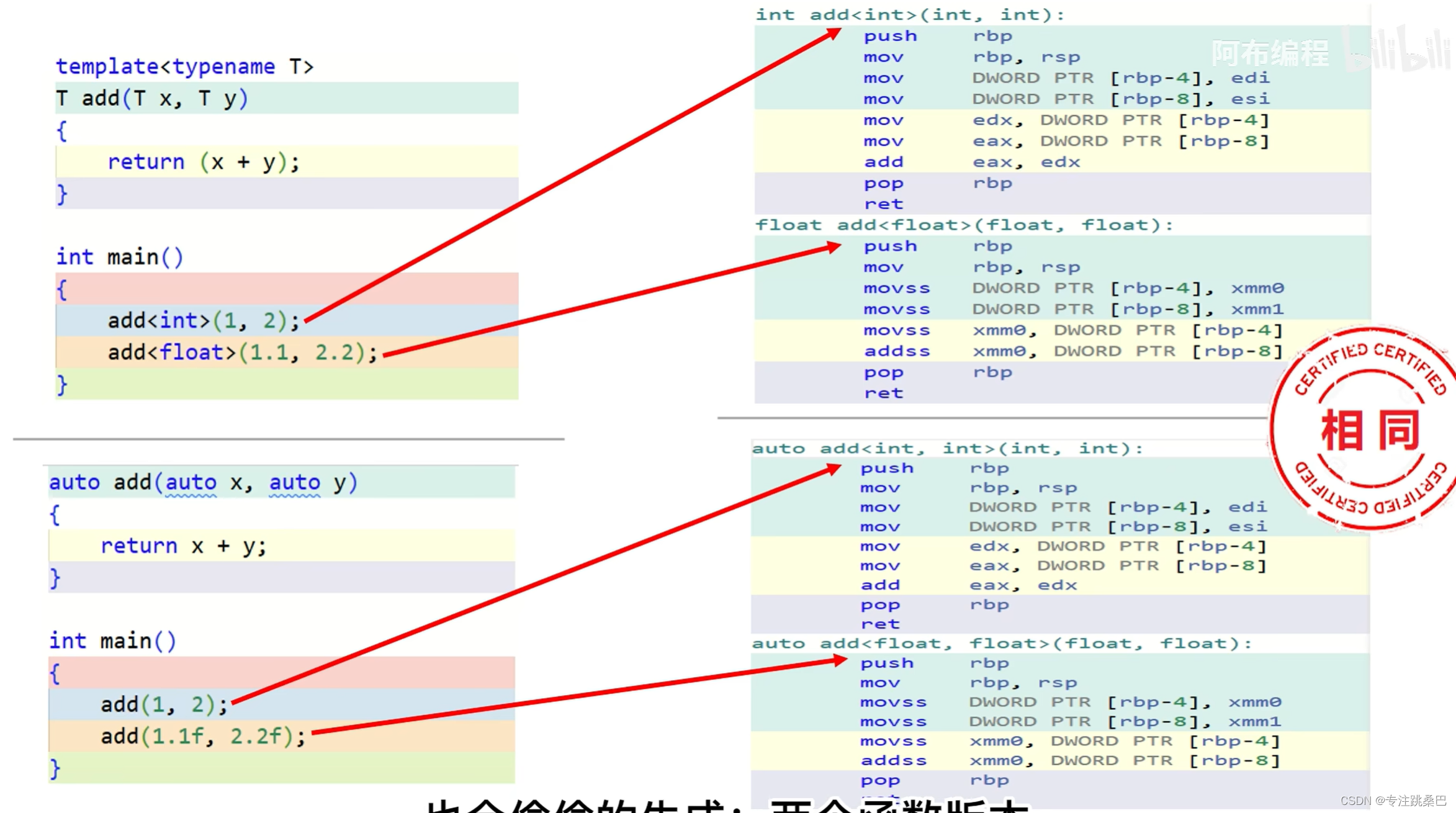
11、auto和模板
- 在template类型中和auto功能差不多,会生成对应的函数
- auto使用引用的时候要特别注意一定要要加&符号


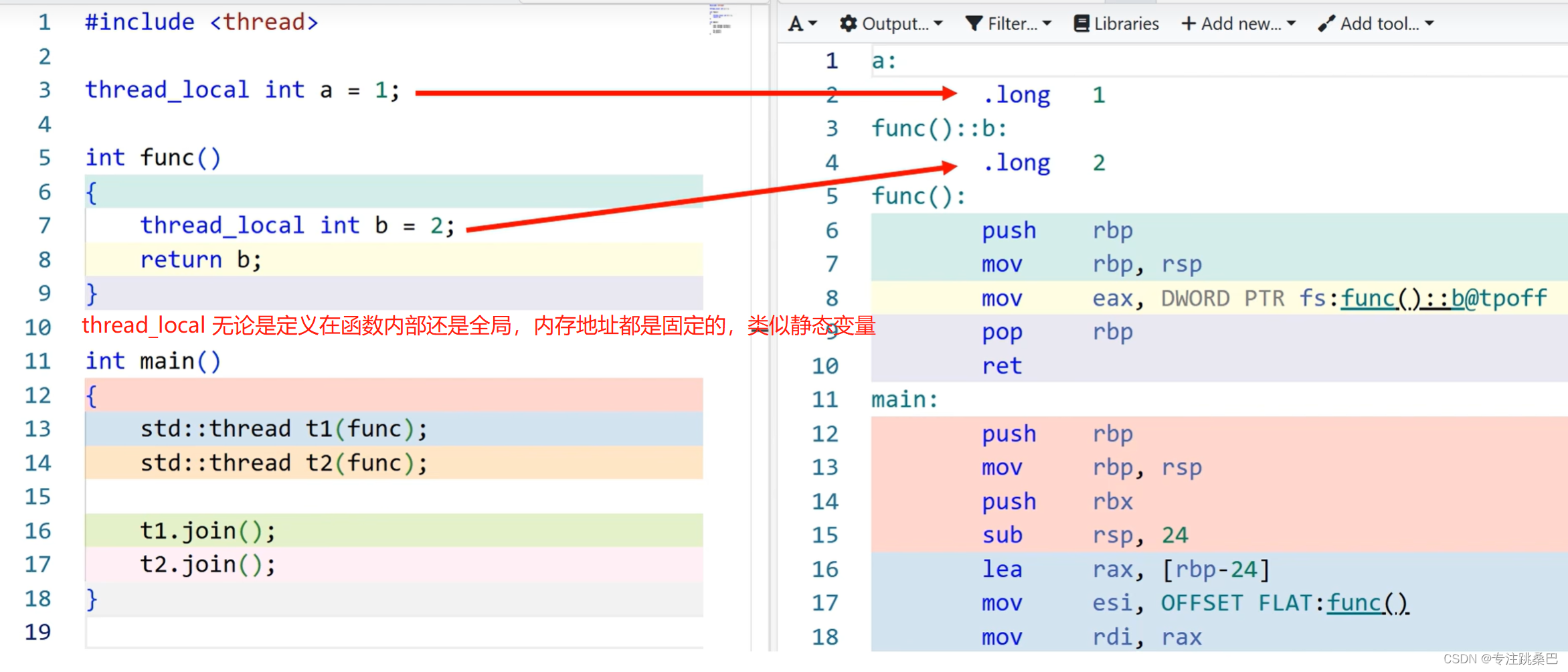
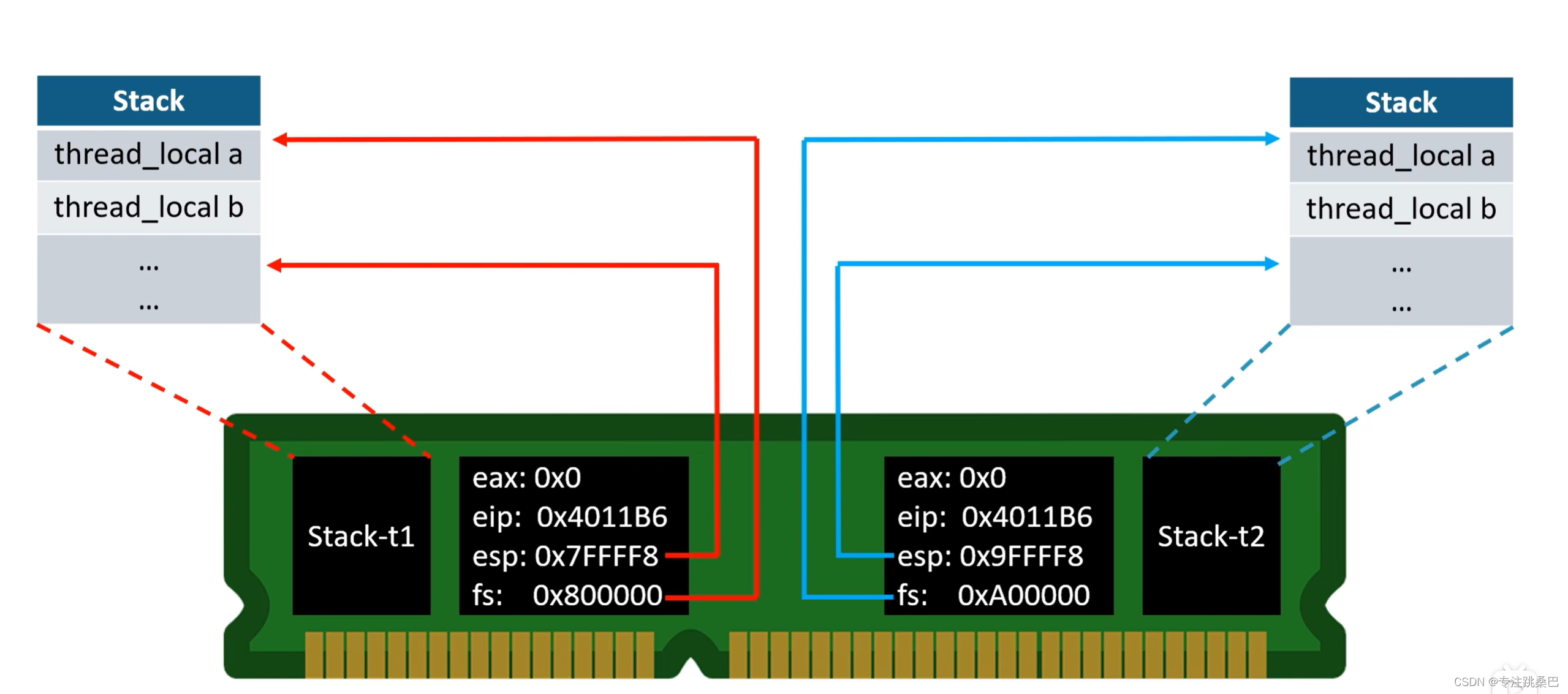
12、thread_local
- thread local关键字与static几乎一致,都将被标注的变量最终落实在全局区或者说数据段。
并且在线程开始时,将这个全局区数据又拷贝在了线程独属的“栈顶”(还要往上),以达到各个线程有一个自己的thread local变量实例
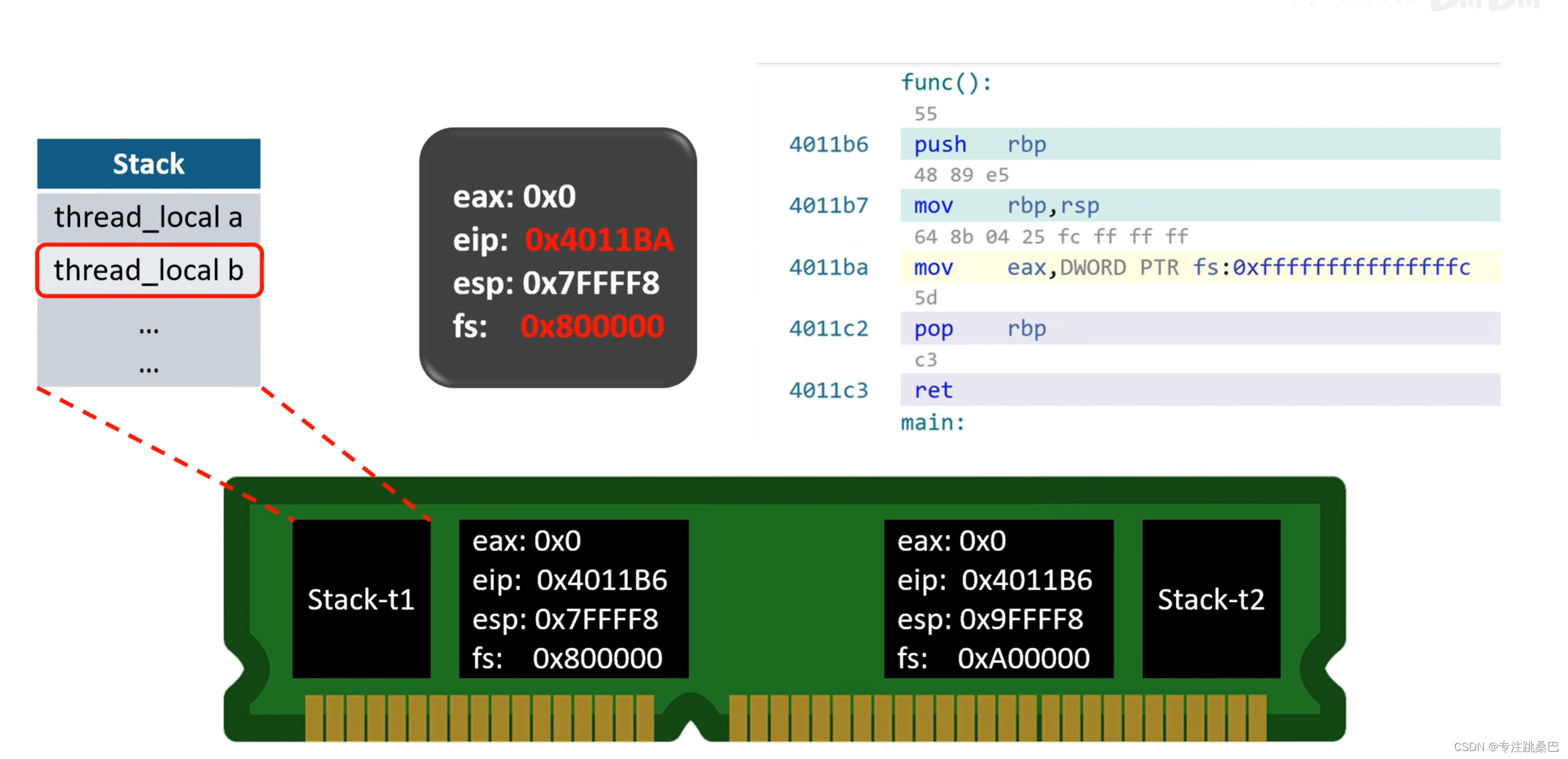
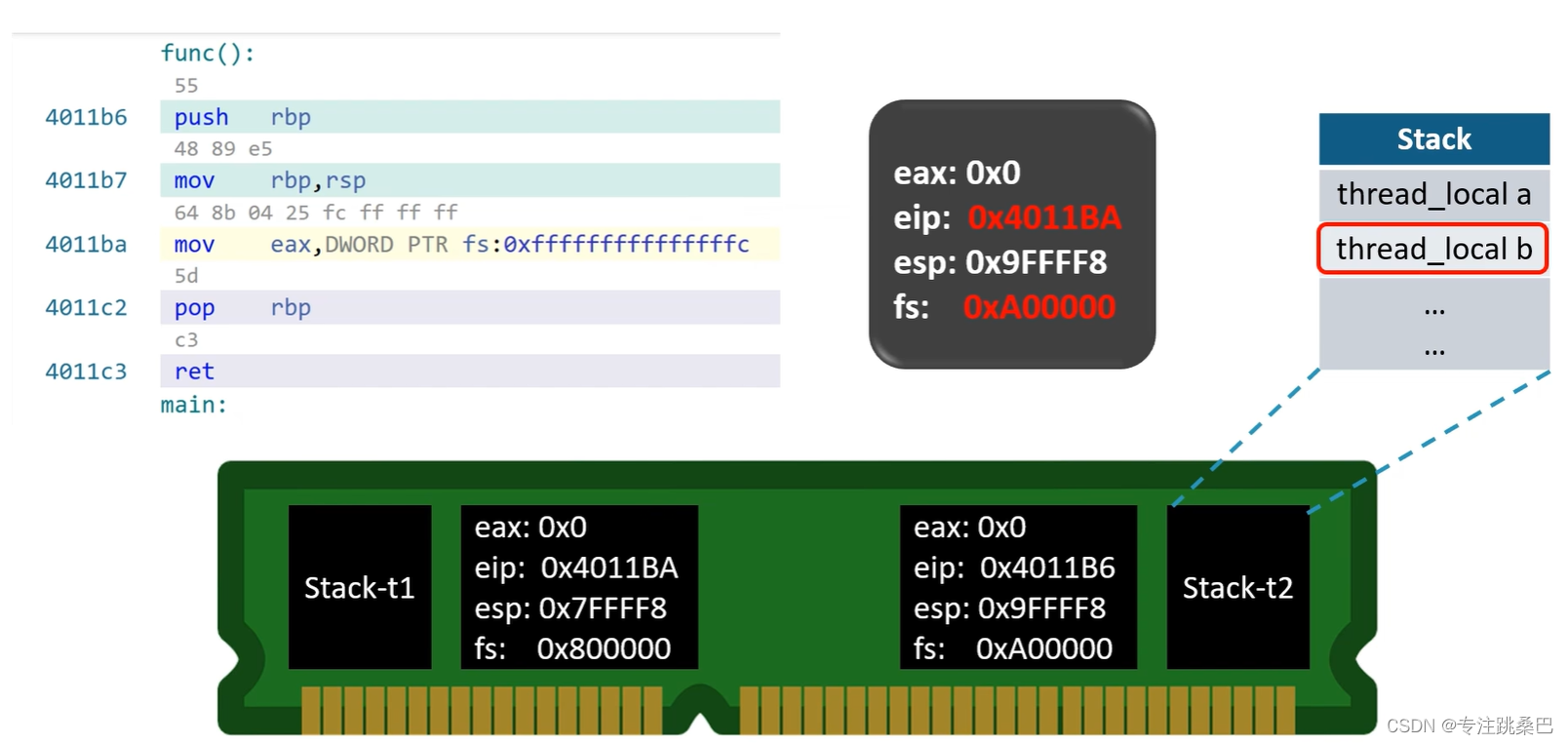
13、函数指针
- 从CPU汇编角度来看,函数可以理解为(函数指针的变量)
- 函数指针如果仅有地址,不知道函数原型无法调用
- 传递函数指针,其实传递是函数的首地址
- 函数指针会损害可读性
- 函数指针也是变量,存的比较特殊而已
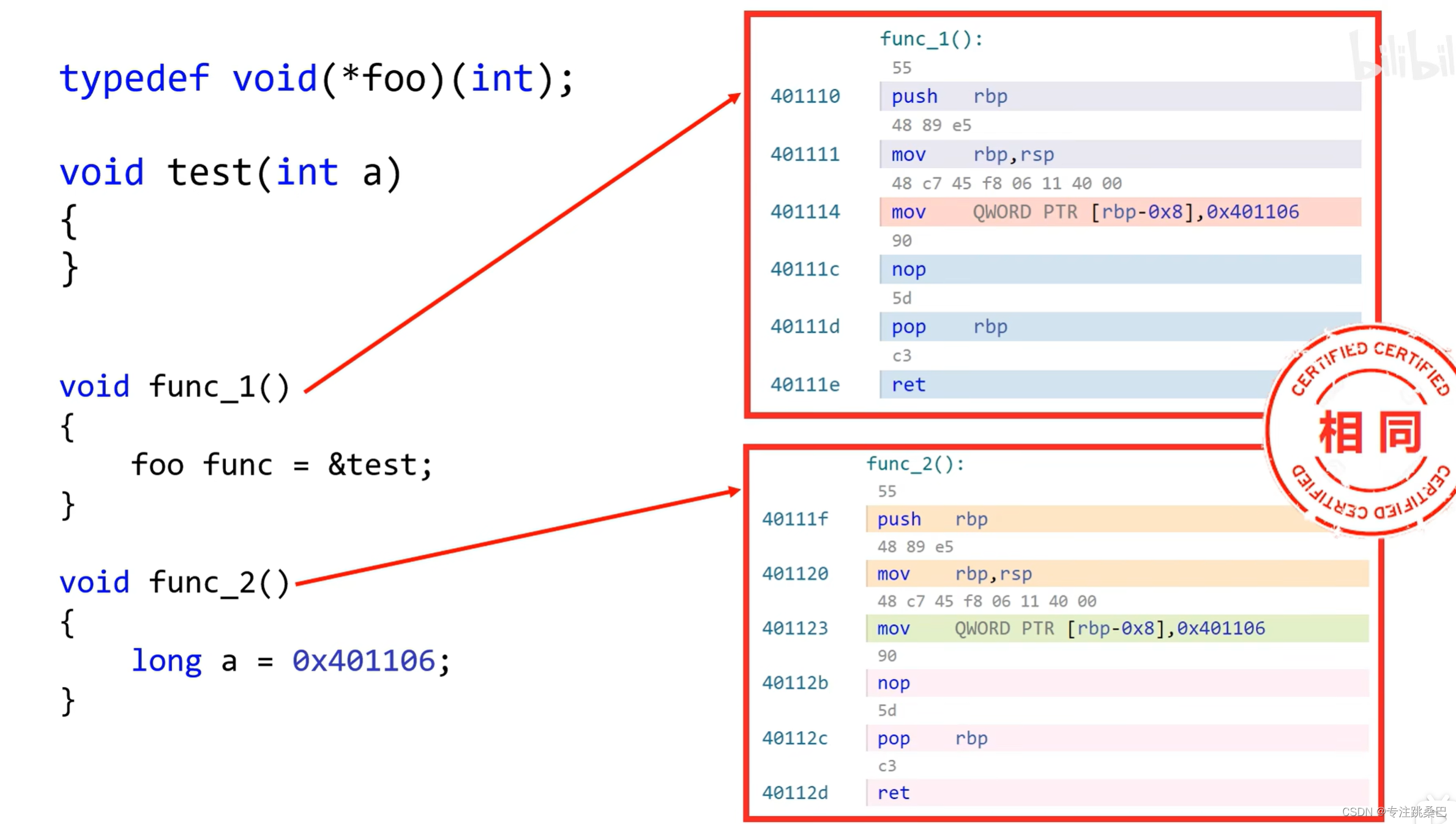
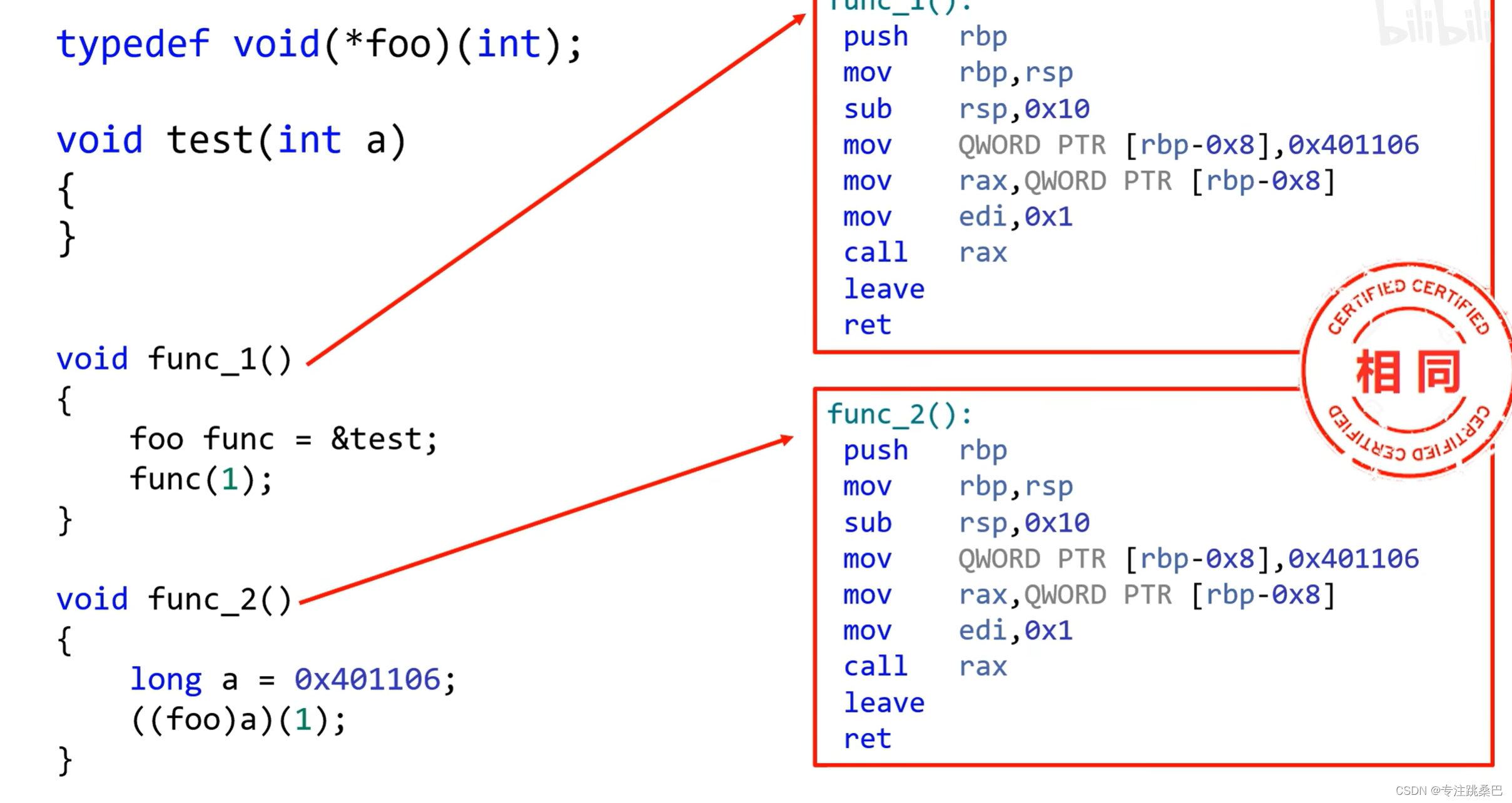
14、goto
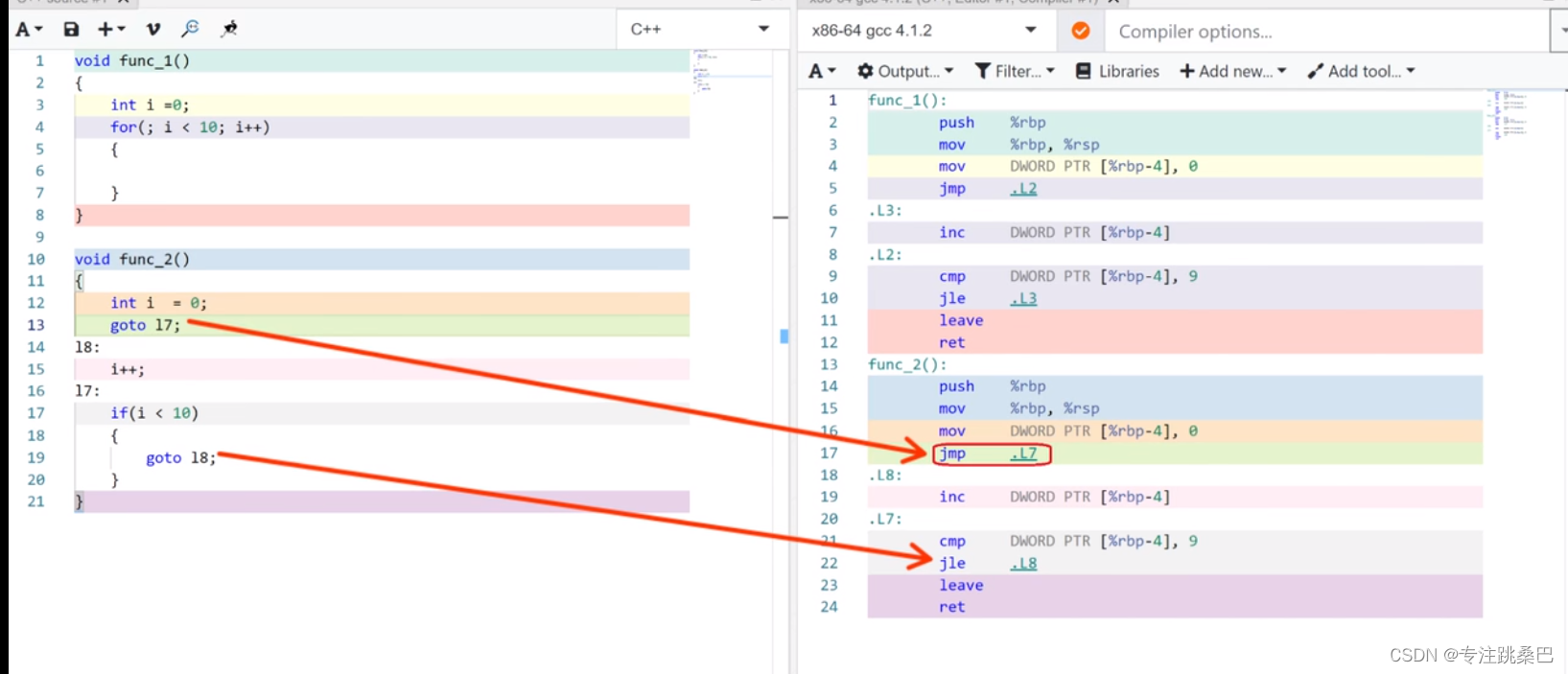
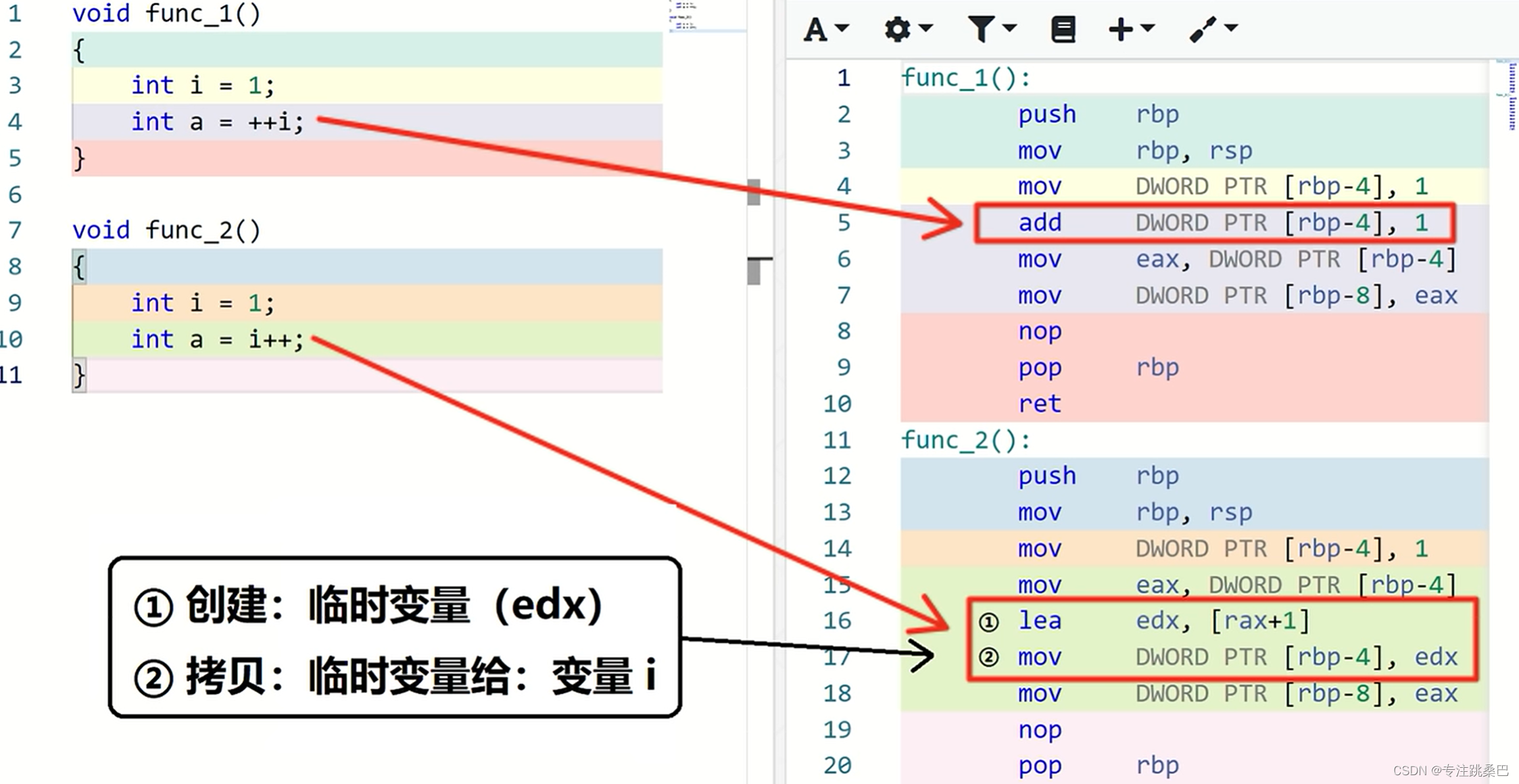
15、i++和++i
- 一般没有差异,赋值的时候有差异
- ++i 返回的是左值,i的引用
- i++返回的是右值,将亡值
- 如果自定义类,重载++,首选前+,少构建一个临时对象

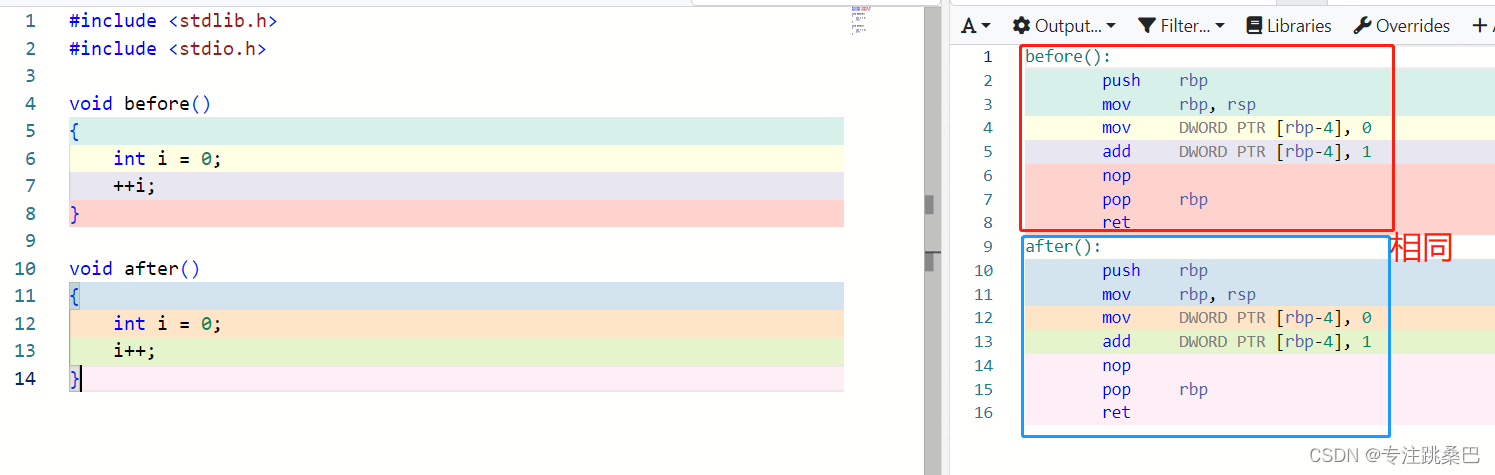
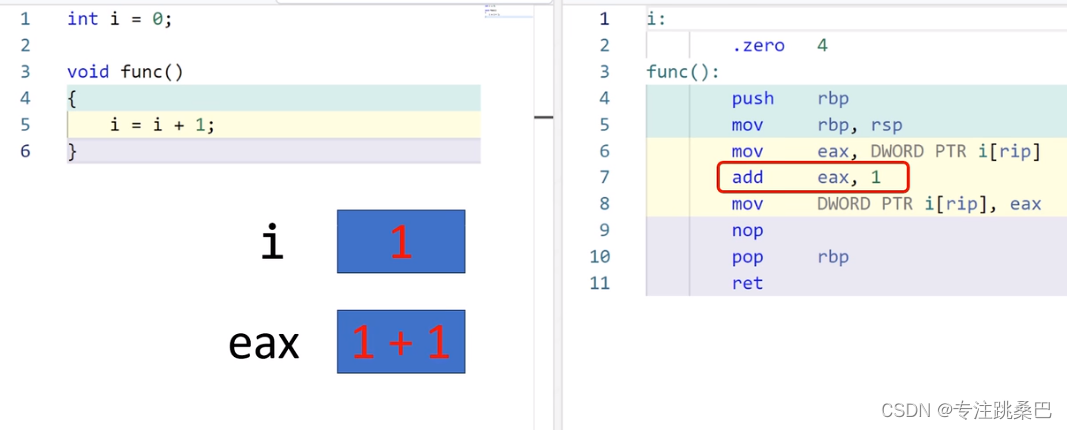
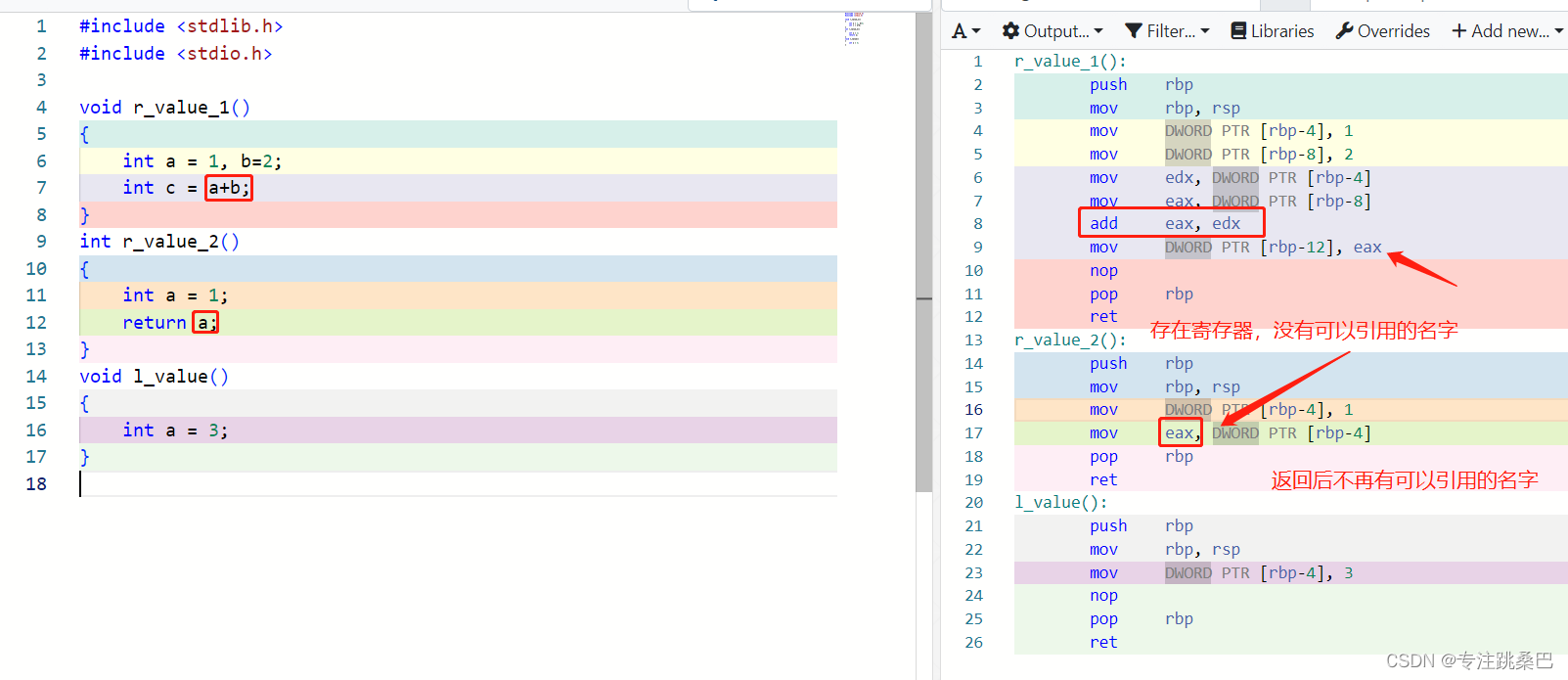
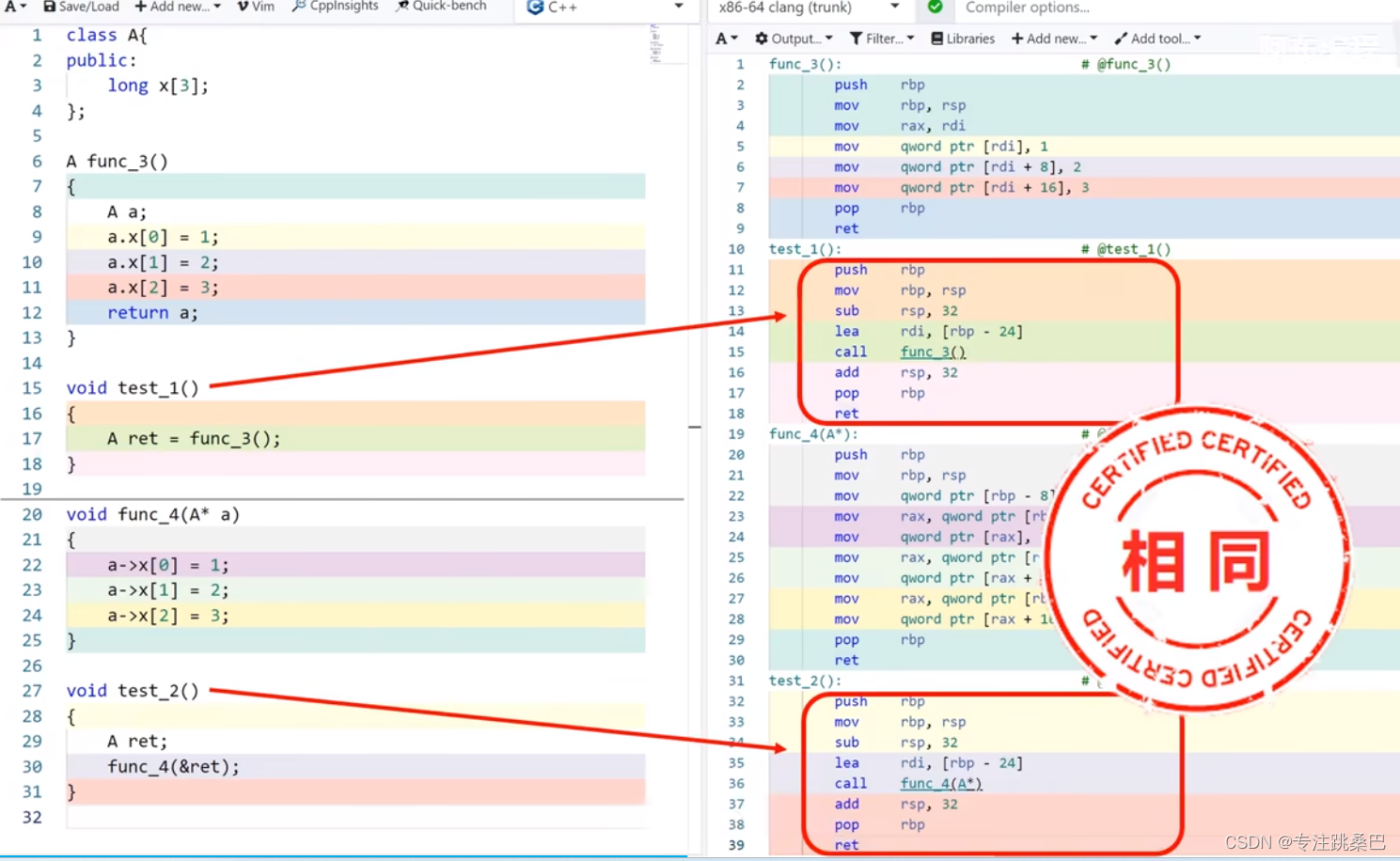
16、左值和右值
- 为什么函数返回临时变量有风险?原理是什么,应该怎么用
- 赋值构造使用临时变量没有风险,原因是本质上变成传指针了
- ++i是左值的,i++是右值的。为什么? 为什么推荐++i

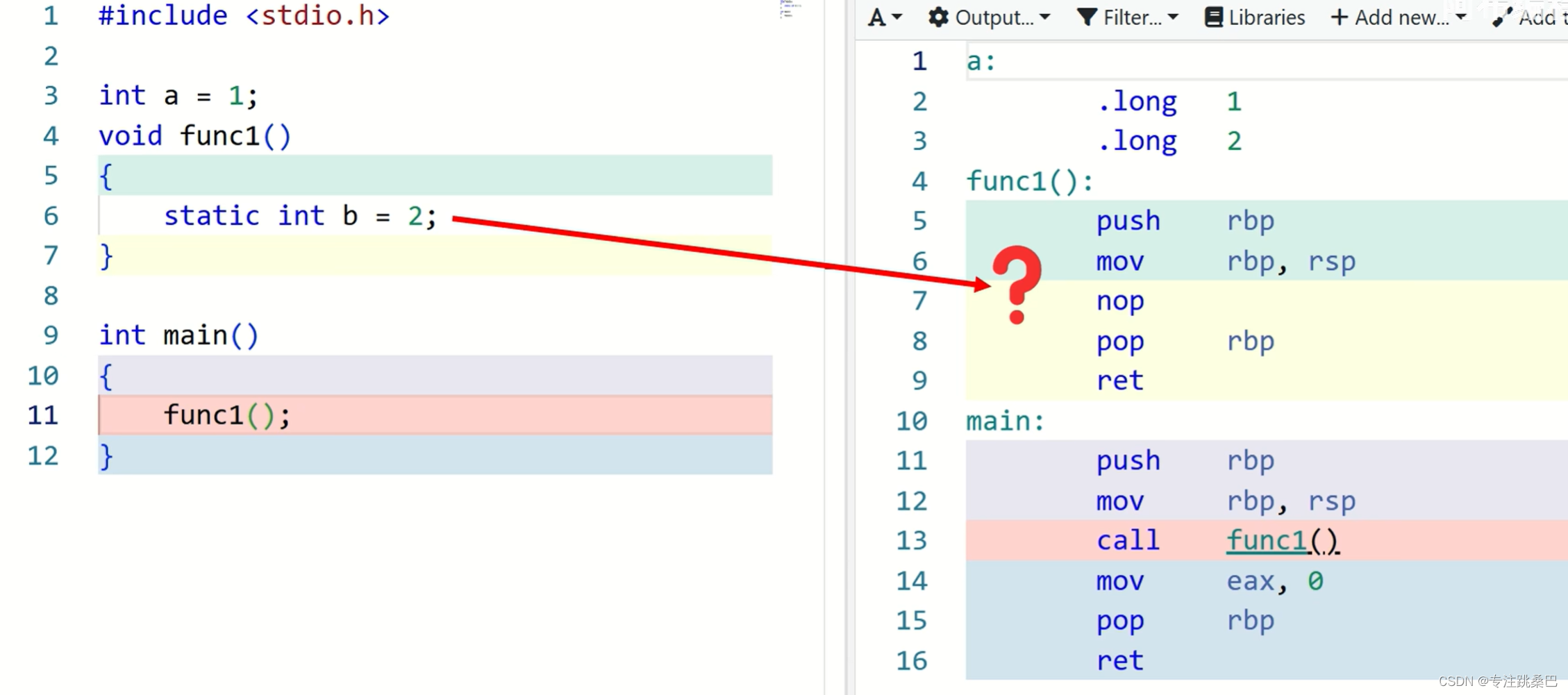
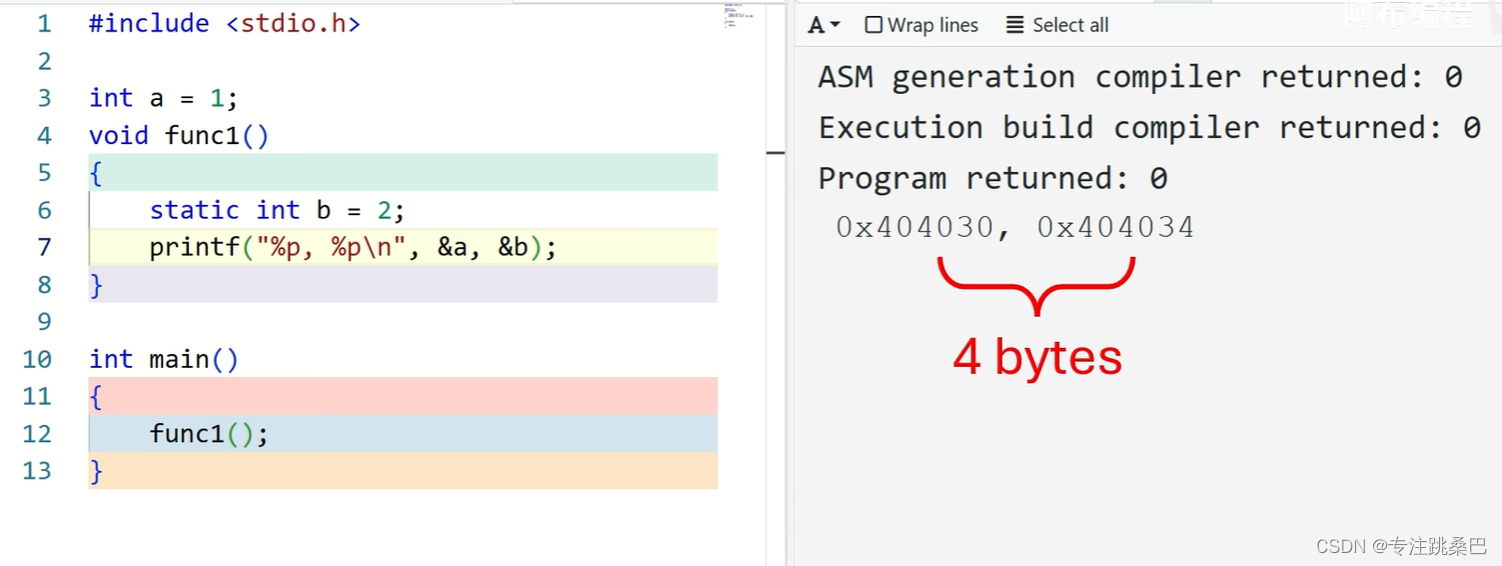
17、静态、全局、临时变量(栈变量)、常量、代码在内存中的分布
- 全局变量和静态变量的内存地址是固定的,栈变量往往不是固定的
- 静态变量和全局变量除了作用域有差别,其他类似
- 全局变量和静态变量如果没有初始化或者初始化为0,会放在未初始化字段,一定程度上节省exe的空间
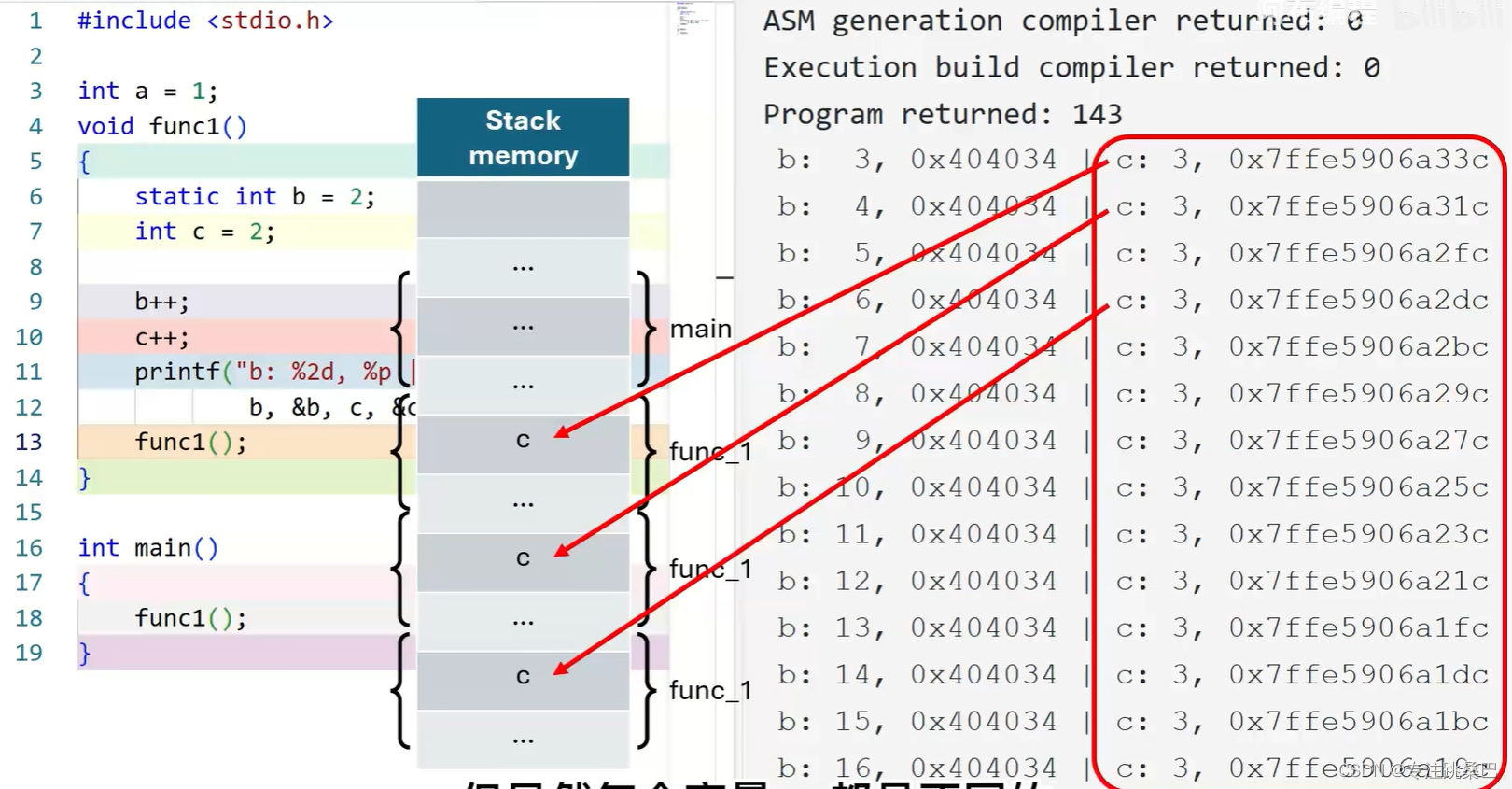
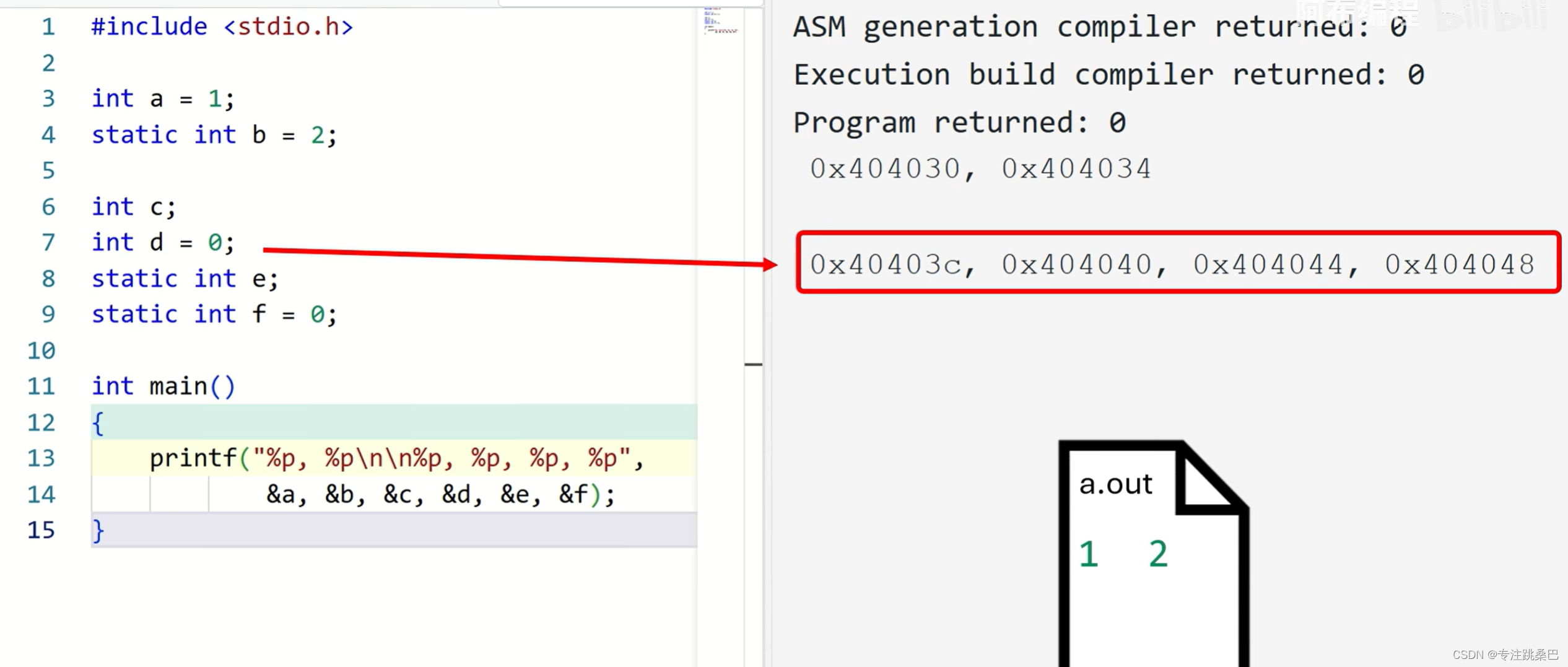
分布特点
#include <iostream>#include <cstdio>
// 在data段的全局变量(已初始化)
int globalVar = 42;
// 在BSS段的全局变量(未初始化)
int globalUninitializedVar;
// 在.rodata段的常量
const char* constString = "This is a constant string";
// text段的函数
void textSegmentFunction() {
std::cout << "Inside a function, part of the text segment.\n";
}
int main() {
// 在stack段的局部变量
int localVariable1 = 1;
int localVariable2 = 2;
int localVariable3 = 3;
// 在heap段动态分配的变量
int* heapVariable1 = new int(10);
int* heapVariable2 = new int(20);
int* heapVariable3 = new int(30);
// 打印各段地址
std::cout << "=== Text Segment[代码段] ===\n";
printf("Address of main: %p\n", (void*)(&main));
printf("Address of textSegmentFunction: %p\n", (void*)(&textSegmentFunction));
std::cout << "\n=== Data Segment[Data段,已经初始化] ===\n";
printf("Address of globalVar: %p\n", (void*)(&globalVar));
std::cout << "\n=== BSS Segment[BSS段,未初始化] ===\n";
printf("Address of globalUninitializedVar: %p\n", (void*)(&globalUninitializedVar));
std::cout << "\n=== .rodata Segment[只读常量.rodata段] ===\n";
printf("Address of constString: %p\n", (void*)(&constString));
std::cout << "\n=== Stack Segment[栈] ===\n";
printf("Address of localVariable1: %p\n", (void*)(&localVariable1));
printf("Address of localVariable2: %p\n", (void*)(&localVariable2));
printf("Address of localVariable3: %p\n", (void*)(&localVariable3));
std::cout << "\n=== Heap Segment[堆] ===\n";
printf("Address of heapVariable1: %p\n", (void*)(heapVariable1));
printf("Address of heapVariable2: %p\n", (void*)(heapVariable2));
printf("Address of heapVariable3: %p\n", (void*)(heapVariable3));
// 释放堆内存
delete heapVariable1;
delete heapVariable2;
delete heapVariable3;
return 0;
}
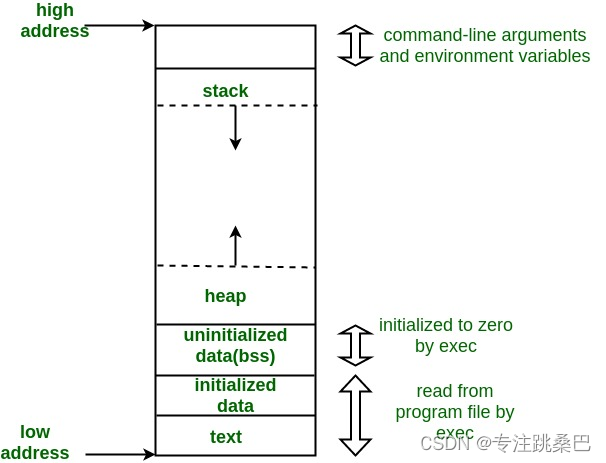
五大区
代码区(text段)
- 内容:这个区域存储程序的机器代码,即编译后的指令。
- 属性:通常是只读的,以防止程序意外地修改自己的指令。
示例:
int main() {// 这部分代码在编译后存储在代码区
return 0;
}
常量区(.roda)
- 内容:存储字符串字面量和常量数据。
- 属性:通常是只读的。
示例:
const int x = 42; // 存储在常量区const char* str = "Hello, World!"; // 字符串字面量也存储在常量区
数据区(Data段)和未初始化的数据(BSS段)
- 内容:存储全局变量、静态变量和一些其他数据。
- 属性:通常分为初始化的数据(Data段)和未初始化的数据(BSS段)。
示例:
int globalVar = 100; // 初始化的全局变量,存储在数据区static int staticVar; // 未初始化的静态变量,也存储在数据区(通常是BSS段)
堆区(Heap)
栈区(Stack)
六个段 bss段,data段、text段、堆(heap)、栈(stack)和.roda
text代码段(Text Segment)
代码段通常存储程序的机器指令,该段也称 .text 段。代码段是只读的,因为程序可以读取但不能写入其中内容。
程序的机器代码(即编译后的代码)。这是程序的主体部分,其中包含了所有函数和方法的实现。
data数据段(Data Segment)
数据段通常存储已经初始化的全局变量和静态变量,该区域也称 .data 段。.data 段是可读写的,普通程序也可以修改其内容。
bss段(Uninitialized Data Segment)
BSS 是 Block Started by Symbol 的缩写,该段存储未初始化的全局变量和静态变量,通常是赋初始值为0的变量。BSS 段也是数据段的一部分,但并不占用可执行代码文件的实际空间(BSS 变量初始值是0,只需要存储它们名字和长度即可,不需要实际存储数据)。因此,BSS 段通常被称为 .bss 段,也是可读写的。
堆区(Heap)
堆区通常用于动态分配内存,它的大小在程序运行期间可以发生变化,该段需要手动分配和释放。在 C++ 中,可以使用 new 和 delete 或 malloc 和 free 等语句,动态地在堆中分配或释放内存空间。
栈区(Stack)
栈区通常用于存储函数调用时所传参数、返回值和局部变量等。在程序执行期间,栈区会自动分配和释放空间,栈空间大小在程序编译时就已预先确定。栈区一般是连续的内存区域,其大小并不能随程序运行发生变化,因此需要注意使用栈区内存时避免溢出等问题。
常量区(Read-Only Data Segment)
常量区用于存储程序中的只读数据,例如字符串常量和全局常量等。在 C++ 中,常量区简称为 .rodata 段。常量区是只读的,因此程序不能对其中的内容进行写入操作。
18、栈对象和堆对象的异同
19、lamda表达式的本质
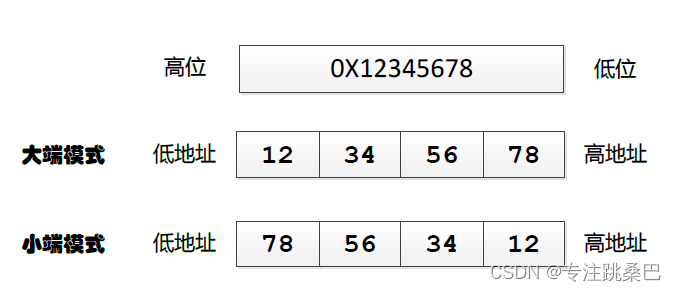
了解即可:大端和小端
系统调用过程
- 处理器所处的模式(有时称为特权级别或环)控制其允许执行的操作
- 现代架构至少有两种选择:内核/管理程序模式和用户模式。虽然一个架构可能支持两种以上的模式,但目前通常只使用
[内核模式]和[用户模式]
- 在内核模式下,一切皆有可能:CPU 可以执行任何支持的指令并访问任何内存。[通常,内核和驱动程序在内核模式下运行]
- 在用户模式下,仅允许指令的子集,I/O 和内存访问受到限制,并且许多 CPU 设置被锁定。[应用程序在用户模式下运行]
- 用户模式程序不能直接访问 I/O 或内存。他们必须向操作系统寻求与外界交互的帮助。
- 程序可以使用特殊的机器代码指令(如 INT 和 IRET)将控制权委托给操作系统。
- 程序不能直接切换权限级别;软件中断是安全的,因为处理器已由操作系统预先配置好要跳转到操作系统代码中的位置。中断向量表只能从内核模式配置。